[Python] #2.2 Navigating with Python (#코딩공부)
<복습>
https://wook-2124.tistory.com/25
[Python] #2.0 What is Web Scraping / #2.1 What are We Building (#코딩공부)
https://youtu.be/s4YWhgfEF68 <복습> https://wook-2124.tistory.com/24 [Python] #1.13 Modules (#코딩공부 #모듈) https://youtu.be/H995Ldft-s4 <복습> https://wook-2124.tistory.com/23 [Python] #1.12 for..
wook-2124.tistory.com
<준비물>
The world's leading online coding platform
Powerful and simple online compiler, IDE, interpreter, and REPL. Code, compile, and run code in 50+ programming languages: Clojure, Haskell, Kotlin (beta), QBasic, Forth, LOLCODE, BrainF, Emoticon, Bloop, Unlambda, JavaScript, CoffeeScript, Scheme, APL, Lu
repl.it
https://github.com/psf/requests
psf/requests
A simple, yet elegant HTTP library. Contribute to psf/requests development by creating an account on GitHub.
github.com
https://www.crummy.com/software/BeautifulSoup/
Beautiful Soup: We called him Tortoise because he taught us.
www.crummy.com
<코드기록>
# requests를 package로 설치하고
# r(rename) = requests.get("url") 한 뒤
# html을 text로 부르는데까지 성공!
import requests
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
print(indeed_result.text)
# 추가로 beautifulsoup4까지 설치완료!
https://www.crummy.com/software/BeautifulSoup/1. requests (Python)

코드표로 보이는 여러 기능들을 사용하기 위해서 Github를 통해서 requests 라이브러리(Library)를 import(수입)해올 수 있다. (준비물에 링크 올려둠)
여기서 라이브러리, 모듈, 프레임워크의 개념에 대해 더 알고싶은 사람들은
https://wook-2124.tistory.com/26?category=892561
[Tip] 라이브러리(Library), 모듈(Module), 프레임워크(Framework)
1. 라이브러리(Library)와 모듈(Module) 라이브러리(Library)는 말 그대로 도서관이라는 뜻을 가지고 있고, 모듈(Module)은 어떤 부분의 구성 단위, 즉 구성부분이라고 생각하면 된다. 개발의 입장에서 보면 라이..
wook-2124.tistory.com
GO GO GO!
2-1. Repl.it에 requests를 설치하기

package에 들어가서 requests 검색해주고!
2-2. Add package

Add Icon을 클릭하면 설치 끝!
3. indeed 홈페이지 조건 설정하기


Advanced job search 통해서 Display 50으로 설정!
4. r = requests.get("url")

여기서 r은 rename을 뜻하는 것 같다. 예를 들어 내가 r을 indeed로 명명하면 그것이 r의 이름이 되는 것!
그럼 여기서 import requests로 라이브러리 기능들을 갖고온 다음에 r을 indeed_result로 개명해주고
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
이렇게 양식에 맞게 코드를 작성해주면 끝!

requests.get을 입력하고 있으면 url을 입력하라는 안내문이 뜨는 것도 알 수 있다.

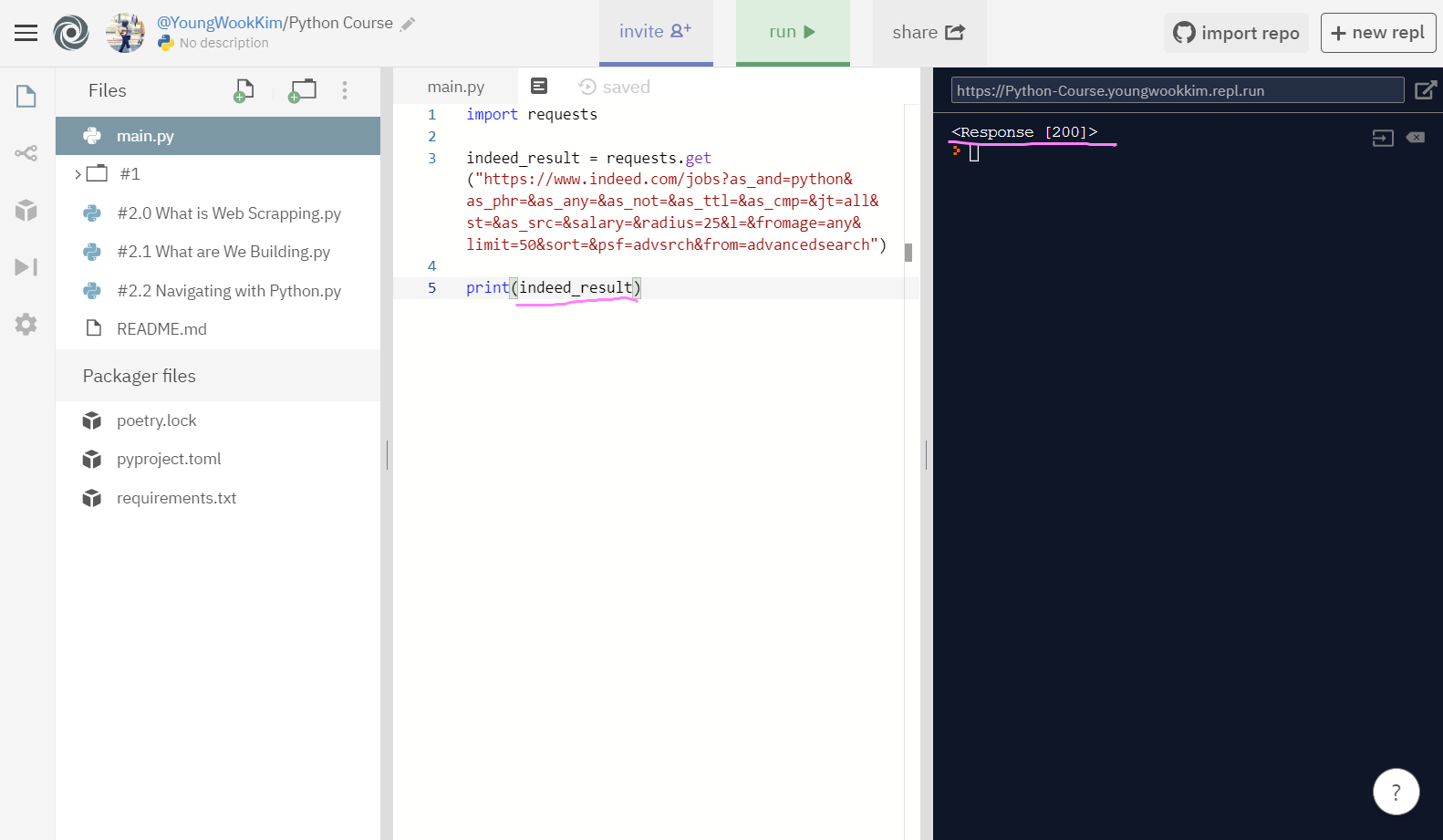
다음으로 print(indeed_result)하기 전에 run(실행)했을 때 오류가 뜨지않고 출력 결과로 Response [200]이 뜨면 기능이 잘 실행된 것!
5. r.text

쉽게 말해서 html(url)안에 들어있는 text를 가져온다고 생각하면 될 것 같다.
여기서 r은 4번에서 정해둔 indeed_result가 된다.

r로 정한 indeed_result뒤에 .text를 붙이고 출력하면 그 안에있는 모든 text들이 출력되는 것을 알 수 있다.
6. BeautifulSoup (Python)

Soup 역시 준비물에 링크를 걸어뒀다. 이것 역시 Web Scraping을 할 때 많이 쓰이는 라이브러리의 한 종류이다.
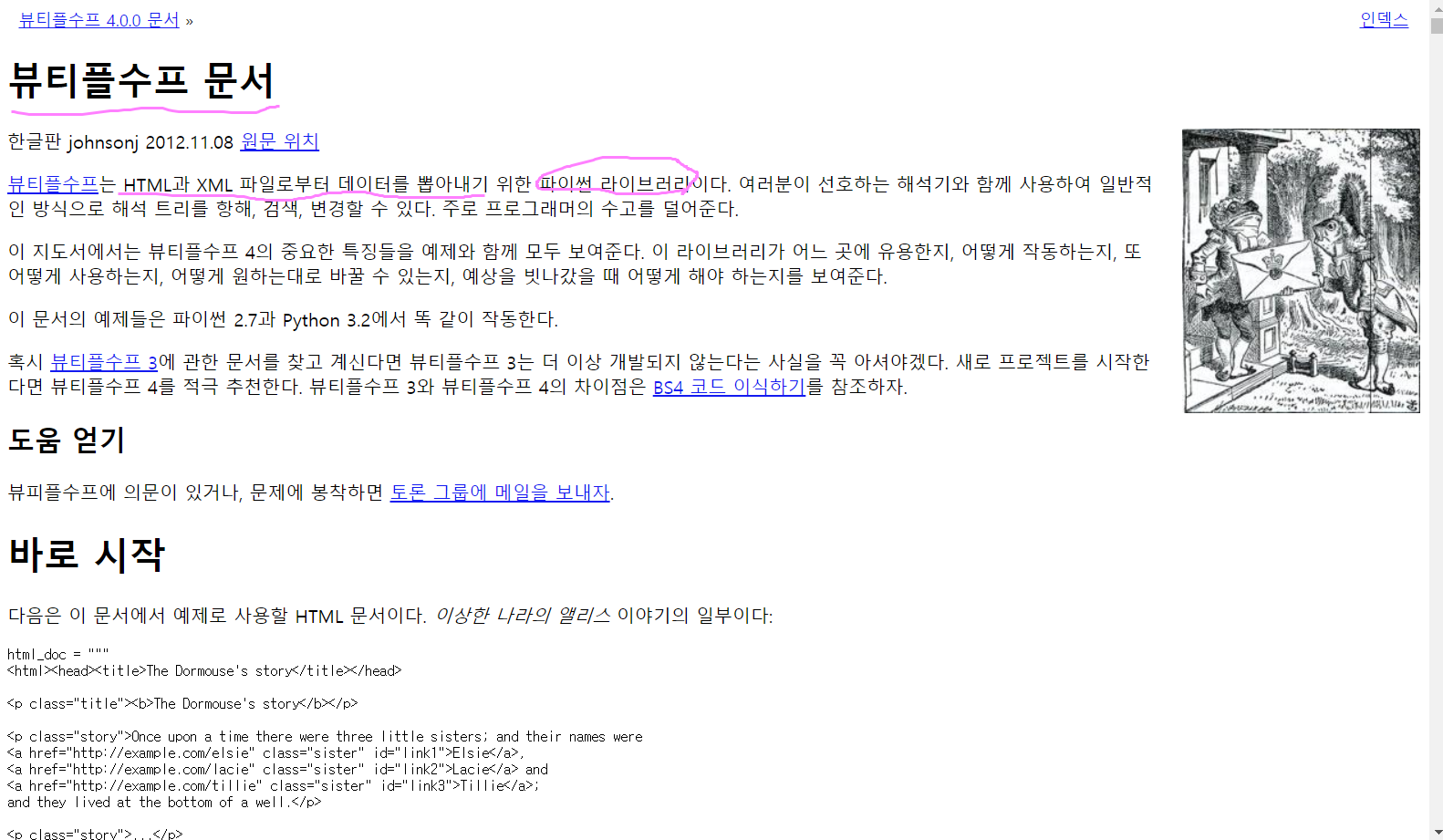
이렇게 한글로도 Documentation(문서)를 읽을 수 있다. 사진에 나온 것처럼 BeautifulSoup는 HTML과 XML 파일로부터 Data를 뽑아내기 위한 Python Library라는 것을 알 수 있다.
설치 및 사용하는 방법은 requests와 동일하다.

package에 가서 beautifulsoup4를 찾고 Add Icon을 클릭하면 끝!!
그러면 requirements.txt(새로 생긴 파일)에 requests와 beautifulsoup4 두 개가 적혀있을 것이다.
총 정리: import requests 라이브러리를 통해 내가 찾고자 하는 URL 주소에 나오는 html의 text를 볼 수 있게 됐다.
BeautifulSoup 라이브러리 사용법은 다음 포스팅에 정리!! :)
※ 신종 코로나 바이러스 조심하세요!!!!
