<복습>
https://wook-2124.tistory.com/29
[Python] #2.3 Extracting Indeed Pages (#코딩공부)
https://youtu.be/O-4tzqK_DB4 <복습> https://wook-2124.tistory.com/27 [Python] #2.2 Navigating with Python (#코딩공부) https://youtu.be/kmH3exe4uZc <복습> https://wook-2124.tistory.com/25 [Python] #2..
wook-2124.tistory.com
<준비물>
The world's leading online coding platform
Powerful and simple online compiler, IDE, interpreter, and REPL. Code, compile, and run code in 50+ programming languages: Clojure, Haskell, Kotlin (beta), QBasic, Forth, LOLCODE, BrainF, Emoticon, Bloop, Unlambda, JavaScript, CoffeeScript, Scheme, APL, Lu
repl.it
https://github.com/psf/requests
psf/requests
A simple, yet elegant HTTP library. Contribute to psf/requests development by creating an account on GitHub.
github.com
https://www.crummy.com/software/BeautifulSoup/
Beautiful Soup: We called him Tortoise because he taught us.
www.crummy.com
<코드기록>
# span에 있는 str만 뽑아내기! .string
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class":"pagination"})
links = pagination.find_all('a')
pages = []
for link in links:
pages.append(link.find("span").string)
page = pages[0:-1]
print(page)
# 굳이 span을 검색하지 않고
# anchor로 검색해도 anchor 안에 있는 span을
# BeautifulSoup이 알아서 찾아줌!
links = pagination.find_all('a')
pages = []
for link in links:
pages.append(link.string)
page = pages[0:-1]
print(page)
# int로 str >> int 변환시켜주기
# links[:-1]로 미리 Next를 포함시키지 않도록 방지!
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
print(pages)
# 기계는 0을 처음으로 인식함 때문에 0 = 2페이지
# 그리고 -1은 마지막 페이지인 20페이지, -2는 19페이지
# 그렇다면 -19는 다시 처음인 2페이지임!
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
print(pages[-19])
# 최종코드
# max_page = pages[-1] 수치까지 입력하고 끝!
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class":"pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]1. soup.title.string (str만 가져오기)

.string을 붙여서 str(문자열)로 바꿔서 값을 가져오자!

<span class="pn">2</span> 에서 2의 str(문자열)값만 뽑아내기 위해서 spans.append(page.find("span"))을 변경하면 되는데 그전에

pages = pagination.find_all('a')에서 pages를 links로, 그리고 spans = [] 에서 spans를 pages로 변수명을 수정해주고, pages.append(link.find("span").string)으로 바꾼뒤, page = pages[0:-1] (첫번째부터 -1값인 Next 전까지) 변수를 만들어서 print(page)로 출력하면 터미널에 보이는 것처럼 str(문자열)로 '2', '3', ..., '20'이 출력된 것을 알 수 있다!
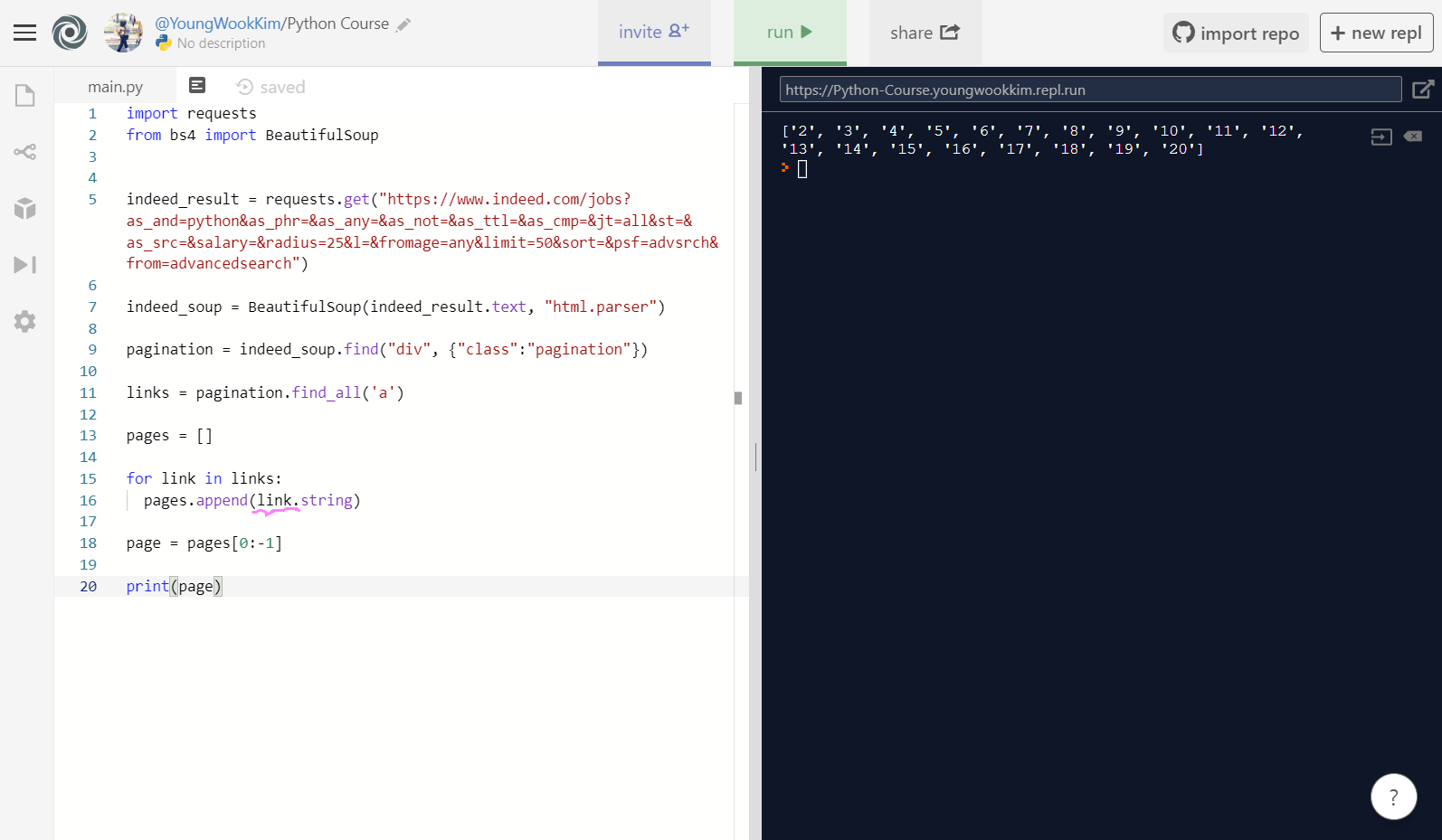
pages.append(link.string) 굳이 .find('span')을 적어서 span을 안찾아도 links인 pagination, anchor가 span 상위에 속하기 때문에 links = pagination.find_all('a')에서 찾은 anchor를 string으로 변환시켜줘도 같은 값이 나온다!

위에 보이는 것처럼 a href=에 span class가 들여써져있는 것을 알 수 있다. 정리하자면, beautifulsoup이 알아서 anchor 안에 있는 span까지 검색해서 찾아주는 것이다!
2. int(integer) 정수만 가져오기

str(문자열)로 뽑아낸 값을 int(integer)로 바꾸려했지만, Next(마지막에 해당하는 값)은 정수로 바꿀 수 없어서 에러가 나왔다.

때문에 for link(새로 구하고자 하는 변수명) in links[:-1]에서 links = pagination.find_all('a')의 마지막 값인 Next에 해당하는 -1을 빼주면 된다.
[] list의 특징: [0]은 처음 값, 그리고 [-1]은 마지막값이다. 그리고 [0:-1]을 입력하면 처음값 ~마지막 전의 값이 된다.
결국 [0:-1] = [:-1]이다. 때문에 사진에 나온 것처럼 코드를 바꿔줘서, 마지막 Next는 호출되지 않게 미리 방지하고(사실은 처음부터 마지막 전의 값을 호출한 것임.) pages.append(int(link.string))으로 string으로 나오는 값('2', '3', '4', ..., '20')을 int로 나오는 값(2, 3, 4, ..., 20)으로 한번 더 바꿔서 출력된 것을 알 수있다.

추가로 기계는 0을 첫 번째로 인식한다!! (중요한 개념이니 한번 더!ㅋㅋㅋ 그리고 0값이 2로 나온 이유는 현재 있는 페이지가 2page이기 때문)

마지막 페이지인 20은 18을 입력하면 된다.
0, 1, 2, 3, 4, ..., 18
2, 3, 4, 5, 6, ..., 20

-1은 마지막 페이지를 의미하므로, 여기서는 pages[18]=pages[-1]임을 알 수 있다.
그러나 수가 더 커질수록 예를 들어, 맨 마지막 페이지가 129538263라고 한다면 이것을 매번 입력하기는 힘드므로, 마지막 페이지를 찾고자 할 때는 -1로 바로 찾는게 더 편하다!

사실 +의 반대 개념인 -가 궁금해서 더 쳐봤다...ㅋㅋㅋㅋㅋ -2는 뒤에서 2번째인 19인 것을 확인할 수 있다!!
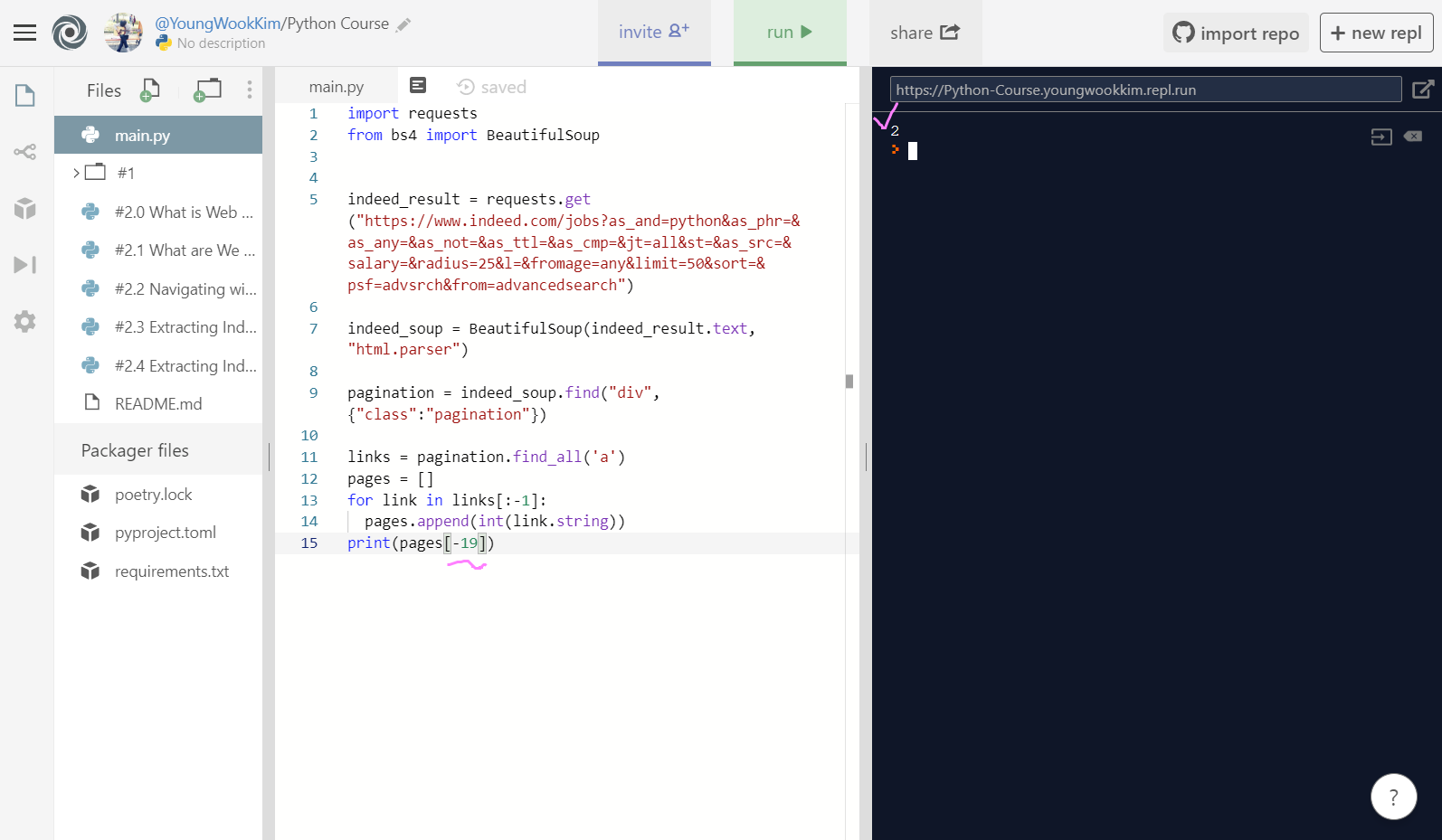
그리고 첫 번째 페이지인 2를 나타내려면, -19를 입력하면 된다.
-1, -2, -3, -4, -5, -6, -7, -8, -9, -10, -11, -12, -13, -14, -15, -16, 17, -18, -19
20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2
정확... ㅋㅋㅋㅋㅋㅋ (멍청멍청)
3. start=50

두 번째 페이지의 URL을 보면 start=50인 것을 확인할 수 있다.

세 번째 페이지의 URL을 보면 start=100인 것을 확인할 수 있다! 그렇다면 첫 번째 페이지의 URL은 아마 start=0일 것이다.
정리하자면, 1page를 기계는 0으로 읽어서 0x50을 하면 0이 나오고, 2page는 1이니 1x50=50, 3page는 2가 되서 50x2=100이라는 값이 나오는 것이다. 그렇다면 마지막 19page는 18로 18x50=900, start=900일 것!
오늘은 span에 있는 값을 string으로 바꿔서 뽑아낸 뒤 string을 다시 int로 바꿨고, 그 과정에서 오류가 났던 Next 수치를 제외하기 위해 [0:-1] = [:-1]를 입력했다, 끝!
※ 코로나바이러스감염증-19 조심하세요!!!!

'Python > Web Scraping' 카테고리의 다른 글
| [Python] #2.6 Extracting Titles (#코딩공부) (0) | 2020.02.19 |
|---|---|
| [Python] #2.5 Requesting Each Page (#코딩공부) (0) | 2020.02.17 |
| [Python] #2.3 Extracting Indeed Pages (#코딩공부) (0) | 2020.02.14 |
| [Python] #2.2 Navigating with Python (#코딩공부) (0) | 2020.02.13 |
| [Python] #2.0 What is Web Scraping / #2.1 What are We Building (#코딩공부) (0) | 2020.02.12 |




댓글