1) 트리 순회방법 ★ __ 2-6, 20년 1, 2, 3회 기출문제
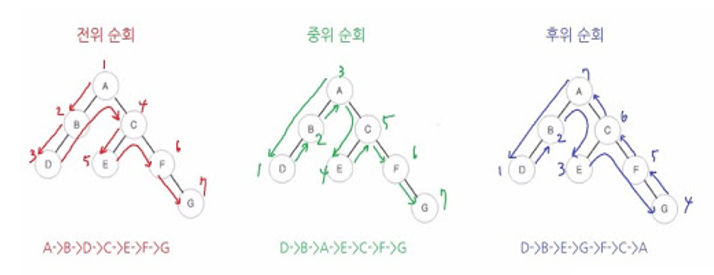
- 전위 순회(Pre-Order Traversal): Root → Left → Right
- 중위 순회(In-Order Traversal): Left → Root → Right
- 후위 순회(Post-Order Traversal): Left → Right → Root
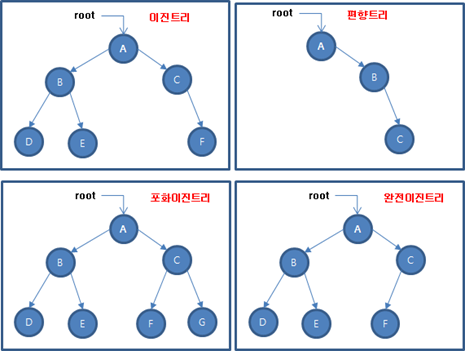
2) 이진 트리 __ 2-6
- 디그리(Degree, 차수)가 2이하인 노드로 구성돼 자식이 둘 이하로 구성된 트리
3) 논리 데이터 저장소 __ 2-9
|
구조 |
설명 |
|
개체(Entity) |
관리할 대상이 되는 실체 |
|
속성(Attribute) |
관리할 정보의 구체적 항목 |
|
관계(Relationship) |
개체 간의 대응 관계 |
#개속관
4) 물리 데이터 저장소 __ 2-13
▶ 논리 데이터 저장소에서 물리 데이터 저장소 모델로 변환하는 절차
단위 개체를 테이블로 변환 → 속성을 컬럼으로 변환 → UID(Unique Identifier)를 기본 키(Primary Key)로 변환 → 관계를 외래 키(Foreign Key)로 변환 → 컬럼 유형(Type)과 길이(Length) 정의 → 반정규화(De-normalization) 수행
5) 인덱스(Index) __ 2-15
- 분포도(Selectivity) 10~15% 이내
▶ 인덱스 컬럼 선정
-수정이 빈번하지 않는 “컬럼”
-ORDER BY, GROUP BY, UNION이 빈번한 “컬럼”
-분포도가 좋은 컬럼은 단독 인덱스로 생성
-인덱스들이 자주 조합되어 사용되는 컬럼은 결합 인덱스로 생성
▶ 설계 시 고려사항
-지나치게 많은 인덱스는 오버헤드(Overhead) 발생
-인덱스만의 추가적인 저장 공간이 필요
-넓은 범위 인덱스 처리 시 오히려 전체 처리보다 많은 오버헤드를 발생시킴
6) 뷰(View) __ 2-16
- 기본 테이블로부터 유도된, 이름을 가지는 가상 테이블로 기본 테이블과 같은 형태의 구조를 사용하며, 조작도 기본 테이블과 거의 같음
- 가상 테이블이기 때문에 물리적으로 구현되어 있지 않지만 사용자에게 있는 것처럼 간주됨
- 데이터의 논리적 독립성을 제공할 수 있음
- 정의된 뷰로 다른 뷰를 정의할 수 있음
- 뷰가 정의된 기본 테이블이나 뷰를 삭제하면 그 테이블이나 뷰를 기초로 정의된 다른 뷰도 자동으로 삭제됨
|
속성 |
설명 |
|
REPLACE |
뷰가 이미 존재하는 경우 재생성 |
|
FORCE |
본 테이블의 존재 여부에 관계 없이 뷰 생성 |
|
NOFORCE |
기본 테이블이 존재할 때만 뷰 생성 |
|
WITH CHECK OPTION |
서브 쿼리 내의 조건을 만족하는 행만 변경 |
|
WITH READ ONLY |
데이터 조작어(DML) 작업 불가 |
▶ 장점
-논리적 데이터 독립성 제공
-접근 제어를 통한 자동 보안 제공
▶ 단점
-독립적인 인덱스를 가질 수 없음
-뷰의 정의를 ALTER로 변경할 수 없음 → DROP하고 새로 CREATE해야 함
-뷰로 구성된 내용에 대한 삽입, 삭제, 갱신, 연산에 제약이 따름
7) 클러스터(Cluster) __ 2-16
- 인덱스의 단점을 해결한 기법 → 분포도(Selectivity)가 넓을수록 오히려 유리함
- 분포도가 넓은 “테이블”의 클러스터링은 저장 공간의 절약이 가능
- 대량의 범위를 자주 액세스(조회)하는 경우 적용
- 인덱스를 사용한 처리 부담이 되는 넓은 분포도에 활용
▶ 클러스터 테이블 선정
-수정이 빈번하지 않는 “테이블”
-ORDER BY, GROUP BY, UNION이 빈번한 “테이블”
-처리 범위가 넓어 문제가 발생하는 경우 단일 테이블 클러스터링
-조인이 많아 문제가 발생되는 경우는 다중 테이블 클러스터링
▶ 설계 시 고려사항
-조회 속도를 향상시켜주지만 입력, 수정, 삭제 시 성능이 저하됨(부하가 증가)
8) 파티션(Partition) __ 2-17, 20년 3회 기출문제
|
종류 |
설명 |
|
레인지 파티셔닝 (Range Partitioning) |
지정한 열의 값을 기준으로 분할 (범위분할) ex) 일별, 월별, 분기별 등 |
|
해시 파티셔닝 (Hash Partitioning) |
해시 함수에 따라 데이터 분할 (해시분할) |
|
리스트 파티셔닝 (List Partitioning) |
미리 정해진 그룹핑 기준에 따라 분할 |
|
컴포지트 파티셔닝 (Composite Partitioning) |
범위분할 이후 해시 함수를 적용 (조합분할) ex) 범위분할 + 해시분할 |
#레해리컴
▶ 파티션의 장점
-성능 향상
- 가용성 향상
- 백업 가능
- 경합 감소
#성가백합
9) PL/SQL __ 2-22
|
구성 |
설명 |
|
선언부 (Declare) |
실행부에서 참조할 모든 변수, 상수, CURSOR, EXCEPTION 선언 |
|
실행부 (Begin/End) |
BEGIN과 END 사이에 기술되는 영역, 데이터를 처리할 SQL문과 PL/SQL 블록을 기술 |
|
예외부 (Exception) |
실행부에서 에러가 발생했을 때 문장 기술 |
#선실예
▶ 장점: 컴파일 불필요, 모듈화 기능, 절차적 언어 사용, 에러 처리
#컴모절에
▶ PL/SQL을 활용한 저장형 객체 활용
-저장된 프로시저, 저장된 함수, 저장된 패키지, 트리거(Trigger)
#프함패트
10) 단위 모듈 구현의 원리 __ 2-32
|
원리 |
설명 |
|
정보 은닉 (Information Hiding) |
어렵거나 변경 가능성이 있는 모듈을 타 모듈로부터 은폐 |
|
분할과 정복 (Divide & Conquer) |
복잡한 문제를 분해, 모듈 단위로 문제 해결 |
|
데이터 추상화 (Data Abstraction) |
각 모듈 자료 구조를 액세스하고 수정하는 함수내에 자료 구조의 표현 내역을 은폐 |
|
모듈 독립성 (Module Inpendency) |
낮은 결합도와 높은 응집도 |
#정분추독
11) 알고리즘 설계 기법 ★ __ 2-92, 20년 3회 기출문제
|
기법 |
설명 |
|
분할과 정복 (Divide and Conquer) |
문제를 나눌 수 없을 때까지 나누고, 각각을 풀면서 다시 병합해 문제의 답을 얻는 알고리즘 |
|
동적계획법 (Dynamic Programming) |
어떤 문제를 풀기 위해 그 문제를 더 작은 문제의 연장선으로 생각하고, 과거에 구한 해를 활용하는 방식의 알고리즘 |
|
탐욕법 (Greedy) |
결정을 해야 할 때마다 그 순간에 가장 좋다고 생각되는 것을 해답으로 선택하는 알고리즘 |
|
백트래킹 (Backtracking) |
어떤 노드의 유망성 점검 후, 유망하지 않으면 그 노드의 부모 노드로 되돌아간 후 다른 자손 노드를 검색하는 알고리즘 |
#분동탐백
12) 시간 복잡도에 다른 알고리즘 ★★ __ 2-93, 20년 1, 2회 기출문제
|
복잡도 |
설명 |
대표 알고리즘 |
|
O(1) |
상수형 복잡도 자료 크기 무관하게 항상 일정한 속도로 작동 ★ |
해시 함수 (Hash Function) |
|
O(log N) |
로그형 복잡도 문제를 해결하기 위한 단계의 수가 log 2N번만큼의 수행 시간을 가짐 |
이진 탐색 (Binary Search) |
|
O(n) |
선형 복잡도 입력 자료를 차례로 하나씩 모두 처리 수행 시간이 자료 크기와 직접적 관계로 변함 (정비례) |
순차 탐색 (Sequential Search) |
|
O(N log N) |
선형 로그형 복잡도 문제를 해결하기 위한 단계의 수가 Nlog 2 N번 만큼 수행 시간을 가짐 |
퀵 정렬 합병 정렬 ★ |
|
O(N2) |
제곱형 주요 처리 루프 구조가 2중인 경우 N의 크기가 작을 땐 N2이 N log 2N보다 느릴 수 있음 |
선택 정렬 버블 정렬 삽입 정렬 ★ |
수제비-NCS 기반 정보처리기사, 산... : 네이버 카페
수제비-수험생 입장에서 제대로 쓴 비법서 (정보처리기사, 정보처리기능사 등 시리즈 수험서)
cafe.naver.com
2020 정보처리기사 필기 총정리 (시나공, 수제비)
본 정리 글은 시나공과 수제비 필기책의 내용을 압축 요약하여 작성했기 때문에 내용이 부족할 수 있습니다. 자세한 내용과 출제 예상문제 및 기출문제를 공부하기 위해서 책을 꼭 참고하시고,
wook-2124.tistory.com
정보처리기사 필기 실기 공부방법 및 기출문제 무료 공유
<네이버페이 5천원 적립 이벤트> 10/18까지 네이버페이 5,000원을 무료로 주는 이벤트가 진행중이니 한번 확인해보세요🙏 네이버페이 포인트 5천원 무료 적립 이벤트! 모르면 손해!! (초간단) 먼�
wook-2124.tistory.com
'정보처리기사 필기 총정리 > 2과목: 소프트웨어 개발' 카테고리의 다른 글
| 2과목 추가 정리: 기출문제 ★★★ (0) | 2020.10.02 |
|---|---|
| 인터페이스 구현 검증 | 인터페이스 오류 확인 ★★ (0) | 2020.10.01 |
| 인터페이스 구현 | 인터페이스 보안 ★★ (0) | 2020.10.01 |
| 모듈 연계 ★★ (0) | 2020.10.01 |
| 애플리케이션 성능 분석 ★★ (0) | 2020.10.01 |




댓글