<복습>
https://wook-2124.tistory.com/44
[Python] #2.14 What is CSV(Comma-separated values) (#코딩공부)
https://youtu.be/t2-yu7e7lFM <복습> https://wook-2124.tistory.com/43 [Python] #2.13 StackOverflow Finish (#코딩공부) https://youtu.be/Ag57YaOl-IQ <복습> https://wook-2124.tistory.com/42 [Python] #2...
wook-2124.tistory.com
<준비물>
The world's leading online coding platform
Powerful and simple online compiler, IDE, interpreter, and REPL. Code, compile, and run code in 50+ programming languages: Clojure, Haskell, Kotlin (beta), QBasic, Forth, LOLCODE, BrainF, Emoticon, Bloop, Unlambda, JavaScript, CoffeeScript, Scheme, APL, Lu
repl.it
https://docs.google.com/spreadsheets
Google 스프레드시트 - 온라인에서 무료로 스프레드시트를 만들고 수정해 보세요.
Excel과 호환 Chrome 확장 프로그램 또는 앱을 사용하여 Microsoft Excel 파일을 열고 수정하고 저장할 수 있습니다. Excel 파일을 Google 스프레드시트로, Google 스프레드시트를 Excel 파일로 변환할 수 있습니다. 더 이상 파일 형식은 신경쓰지 마세요.
www.google.com
<코드기록>
# open(파일을 열어주는 역할)함수, mode(읽기전용과 쓰기전용으로 나뉨)
# mode에서 읽기전용은 read(r)이고, 쓰기전용은 write(w)을 뜻함
# writer = csv.writer(file)의 의미 - writer란 우리가 정한 'file'이라고 저장한 변수를 csv로 쓰겠다는 것을 정하는 변수
# writer.writerow()의 의미 - writer 변수로 정한 쓰기권으로 write_row(행) 즉, 행을 추가한다는 뜻
import csv
def save_file(jobs):
file = open("jobs.csv", mode="w")
writer = csv.writer(file)
writer.writerow(["title", "company", "location", "link"])
print(jobs)
return
# indeed.py 원본
# 수업진행 할 때, 모든 페이지를 갖고오면 시간이 많이 걸려서 2페이지만 가져오는 함수로 바꿔놨음
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_job(html):
title = html.find("div", {"class": "title"}).find("a")["title"]
company = html.find("span", {"class": "company"})
company_anchor = company.find("a")
if company:
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
else:
company = None
location = html.find("div", {"class": "recJobLoc"})["data-rc-loc"]
job_id = html["data-jk"]
return {
'title': title,
'company': company,
'location': location,
"link": f"https://www.indeed.com/viewjob?jk={job_id}"
}
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
print(f"Scrapping Indeed: Page: {page}")
result = requests.get(f"{URL}start={page * LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs
# jobs에 있는 각 job을 가지고 row(행)를 작성함
# job이 가진 값의 list를 row(행)로 가져올 것임
import csv
def save_file(jobs):
file = open("jobs.csv", mode="w")
writer = csv.writer(file)
writer.writerow(["title", "company", "location", "link"])
for job in jobs:
writer.writerow(list(job.values()))
return1. open 사용하기 (mode="w, r")
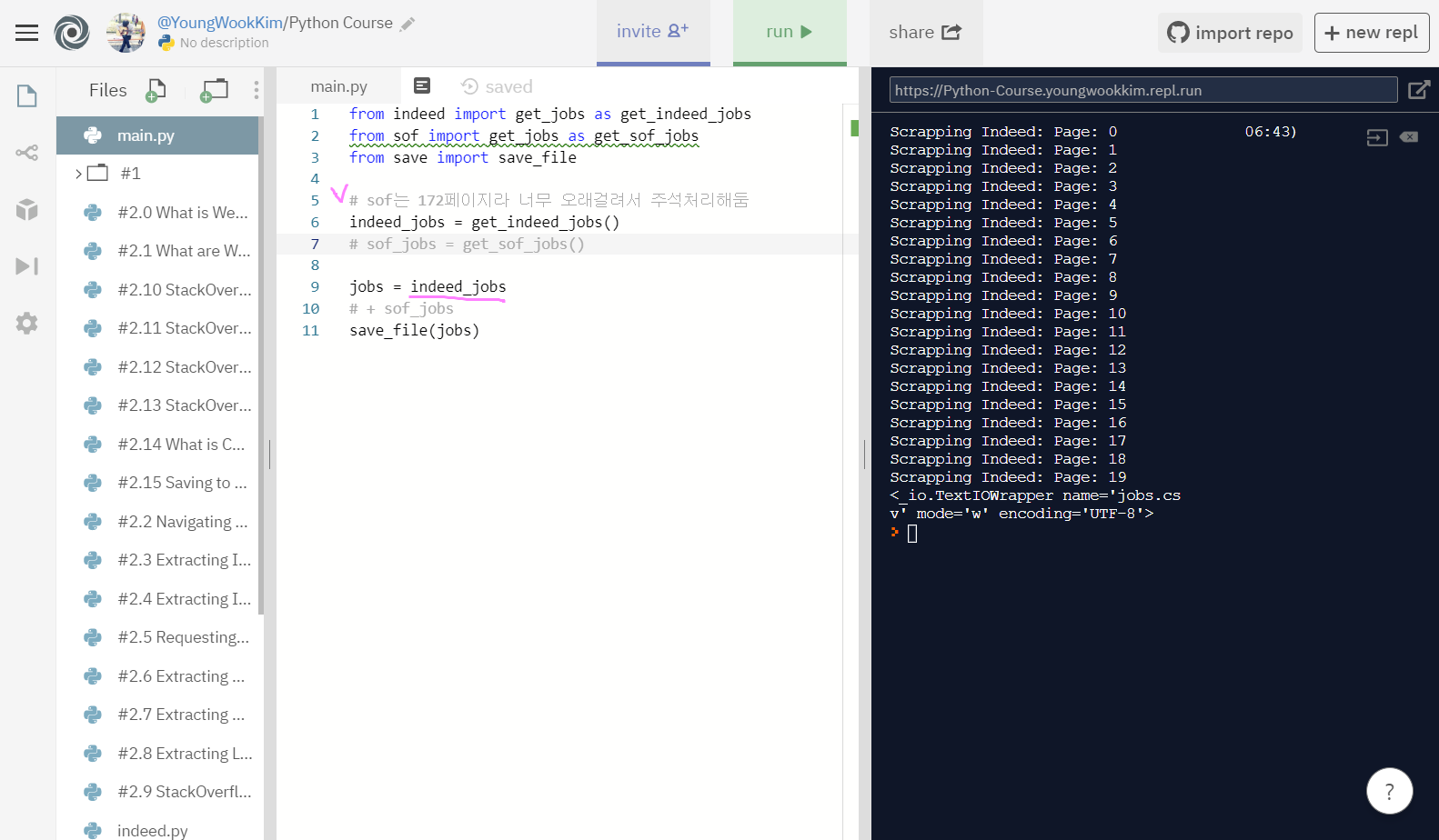
먼저 stackoverflow page는 총 172페이지나 되므로 주석처리하고, indeed page(총 20page)만 csv파일로 옮겨보자.
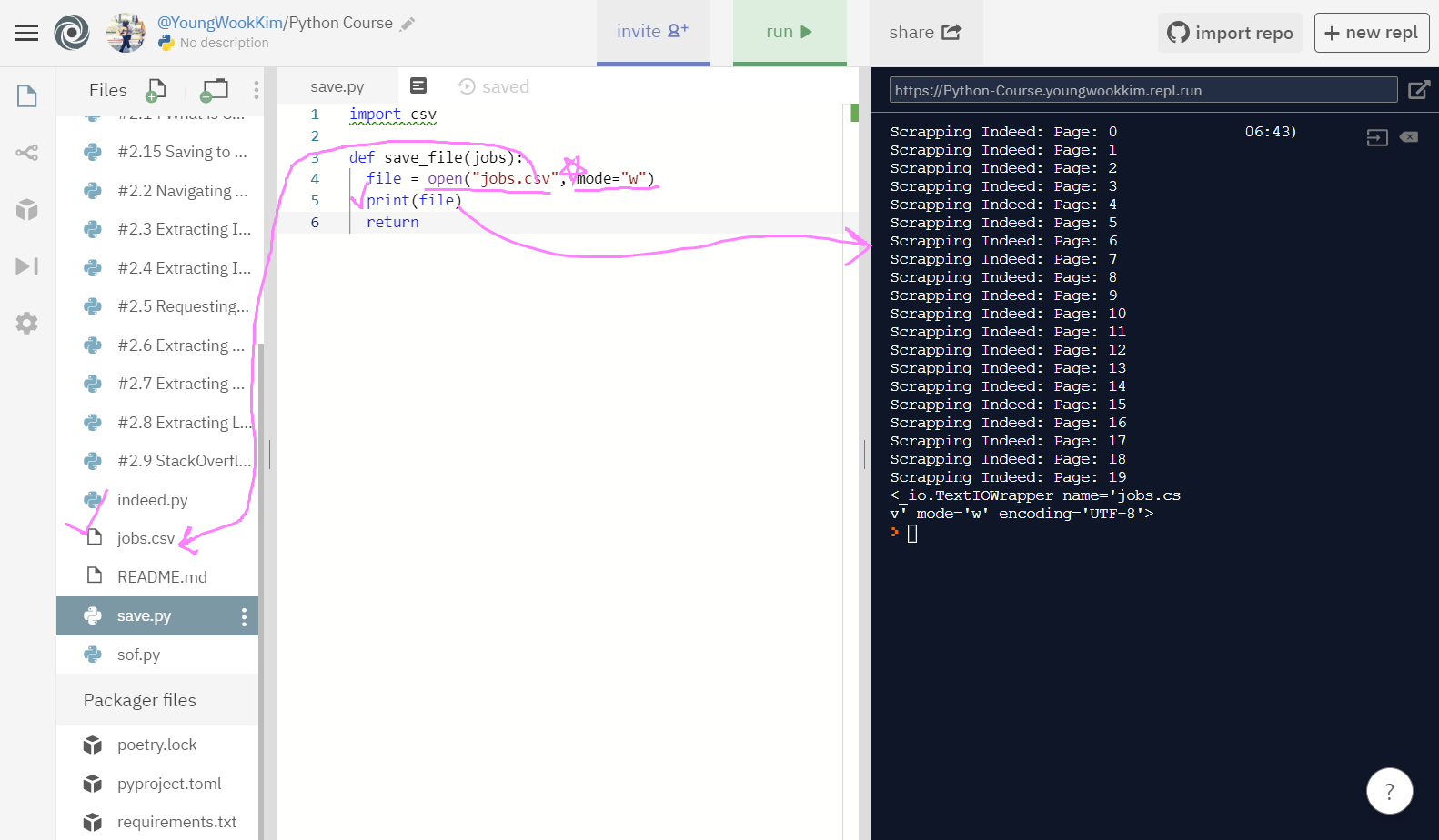
open 기능은 말 그대로 파일을 열때 사용하는 것이다. open("jobs.scv")는 jobs.scv 파일을 open되게끔 설정하는 것이고 mode="w"는 밑에서 설명하겠다.
그럼 mode는 무슨 기능을 할까? 먼저 파일을 open(열 때)에는 다양하게 mode를 지정할 수 있다.
mode에는 read mode(읽기전용)과 write mode(쓰기전용)이 있는데, mode="w"는 only to write, 즉 쓰기전용이라는 뜻이 된다. (그럼 반대로 mode="r"은 읽기전용!)
만약 jobs.csv 파일에 어떤 다른 외부의 글자가 써지더라도 mode를 w로 설정하면, open 함수 실행 시 jobs.csv 파일에 적은 내용은 비워지고 적고자하는(write) 내용이 csv 파일로 채워진다.
실행을 해보면 jobs.csv라는 파일이 open되서 생성된 것을 알 수 있다.
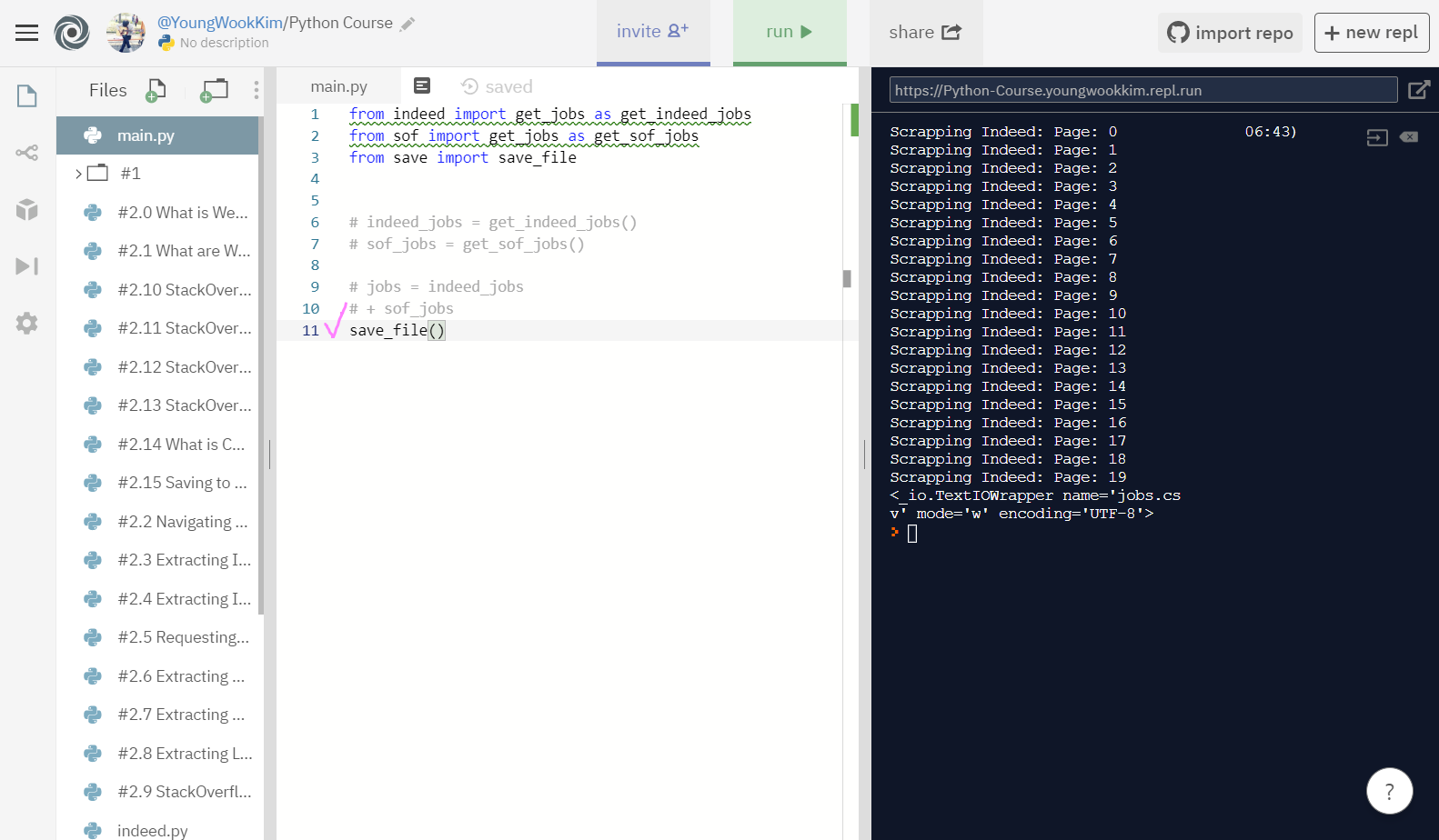
open 기능이 실행되기 전에 추출이 먼저 되므로, mode='w' 실험을 위해 sof와 indeed 실행처리를 모두 주석처리했다.
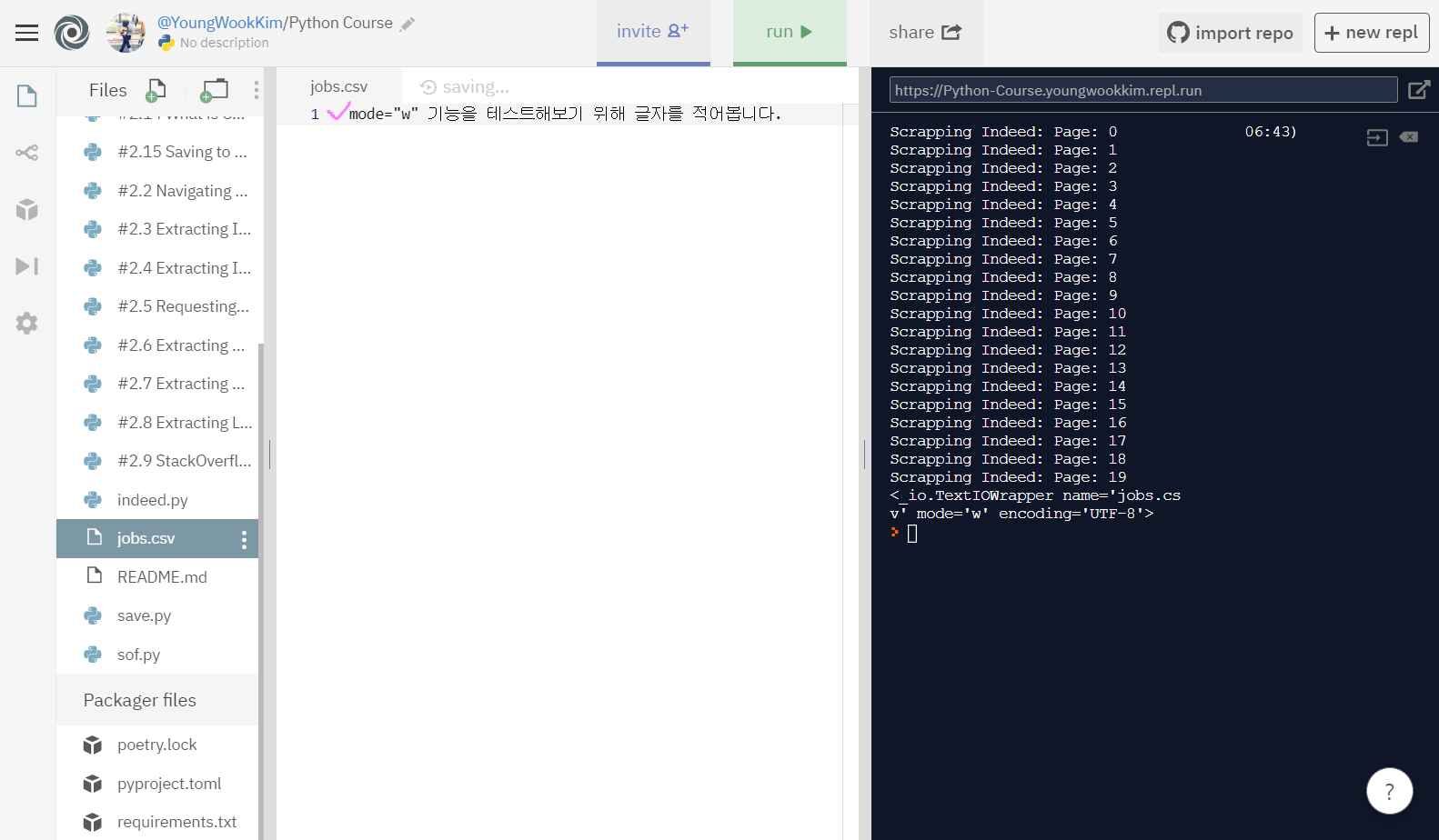
과연 미리 적어둔 내용이 없어질지 실험해보자.
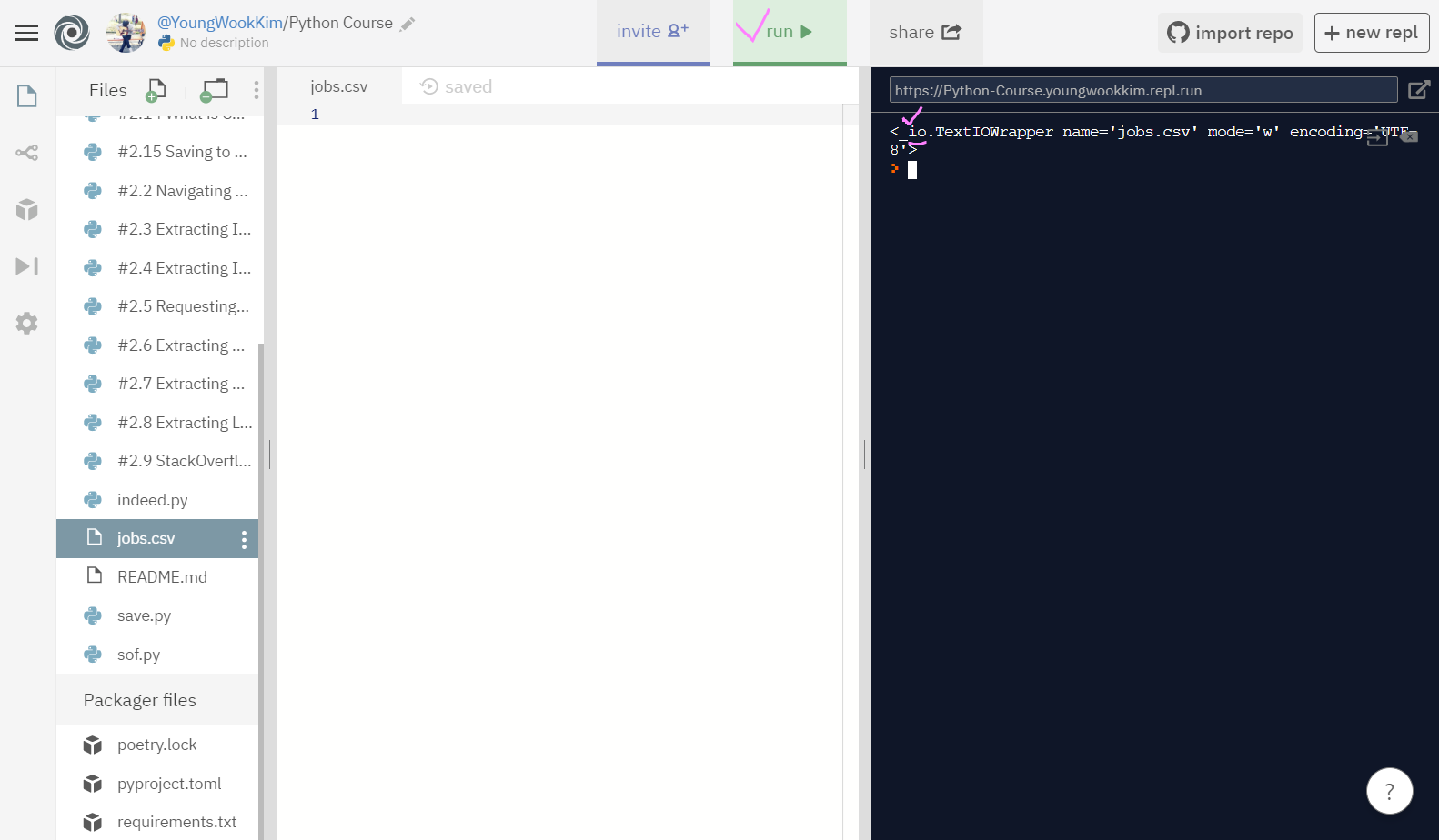
실행결과, jobs.csv 파일에 써둔 글자가 사라진 것을 알 수 있다.
또 터미널 출력결과를 보면 io가 있는데 이것은 input, output도 우리가 원하는대로 수정할 수 있음을 뜻한다.
2. writer 사용하기
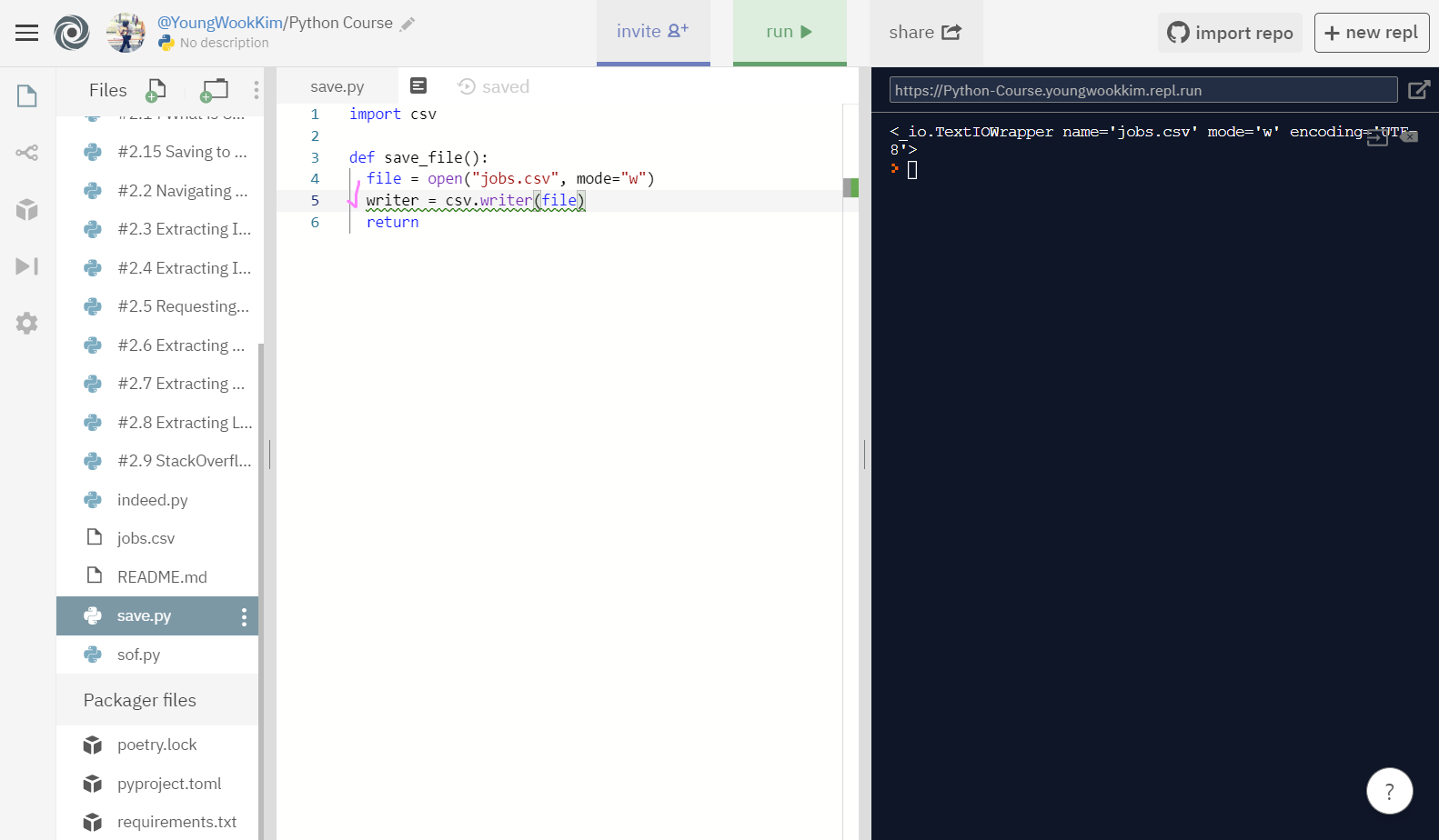
writer란 내가 'file'이라고 정한 변수명을 csv파일의 writer로 정하겠다는 것을 정하는 변수이다.
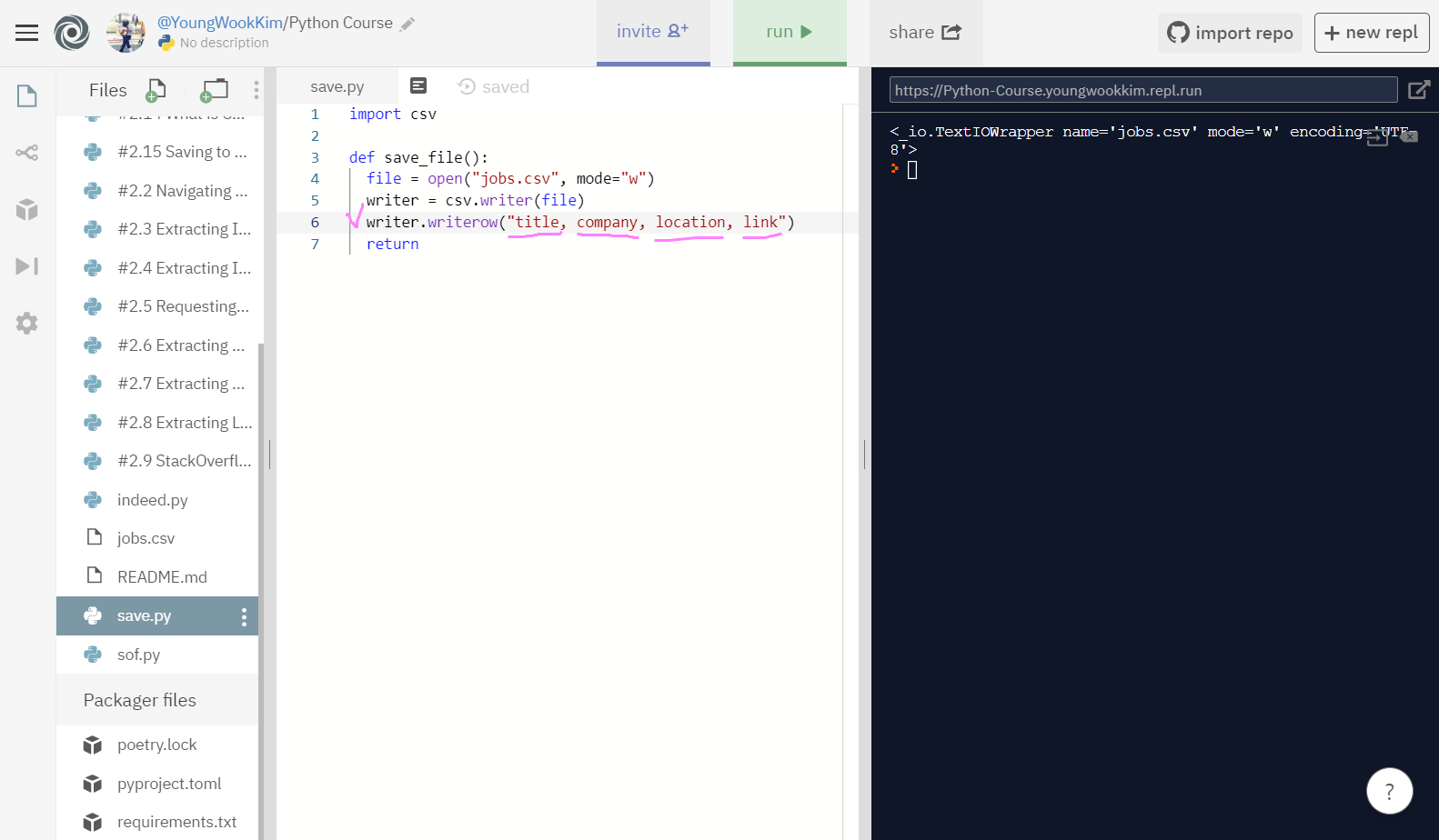
writer.writerow()의 의미는 writer로 정한 쓰기권으로 write_row(행) 즉, 행을 추가한다는 뜻이다.
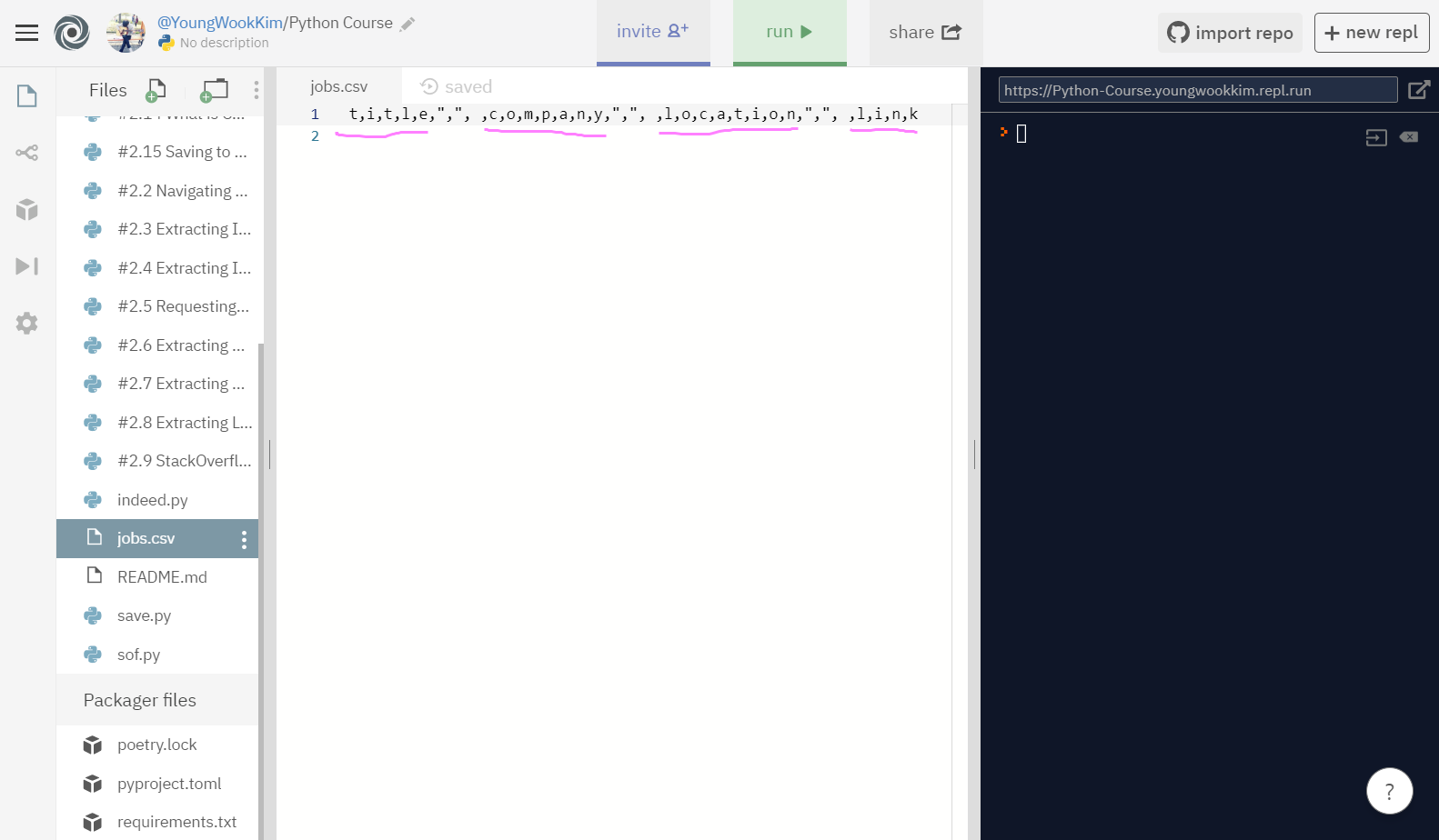
하지만 실행결과 엉망으로 나와서 [] - link로 묶어서 실행해보도록 하겠다.
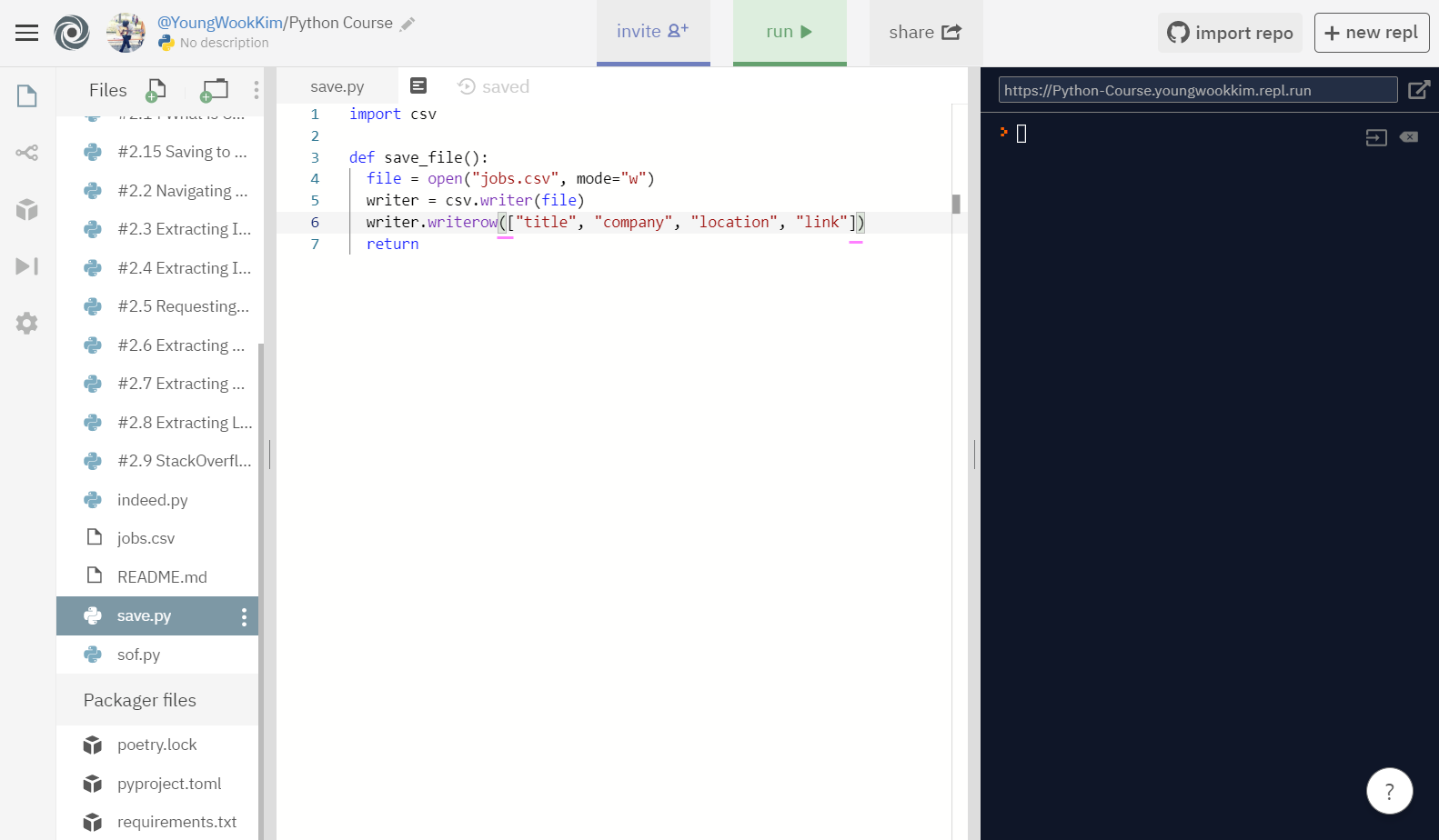
다시 row(행)으로 추출하고 싶은 것들을 [] link로 묶어주고 실행!
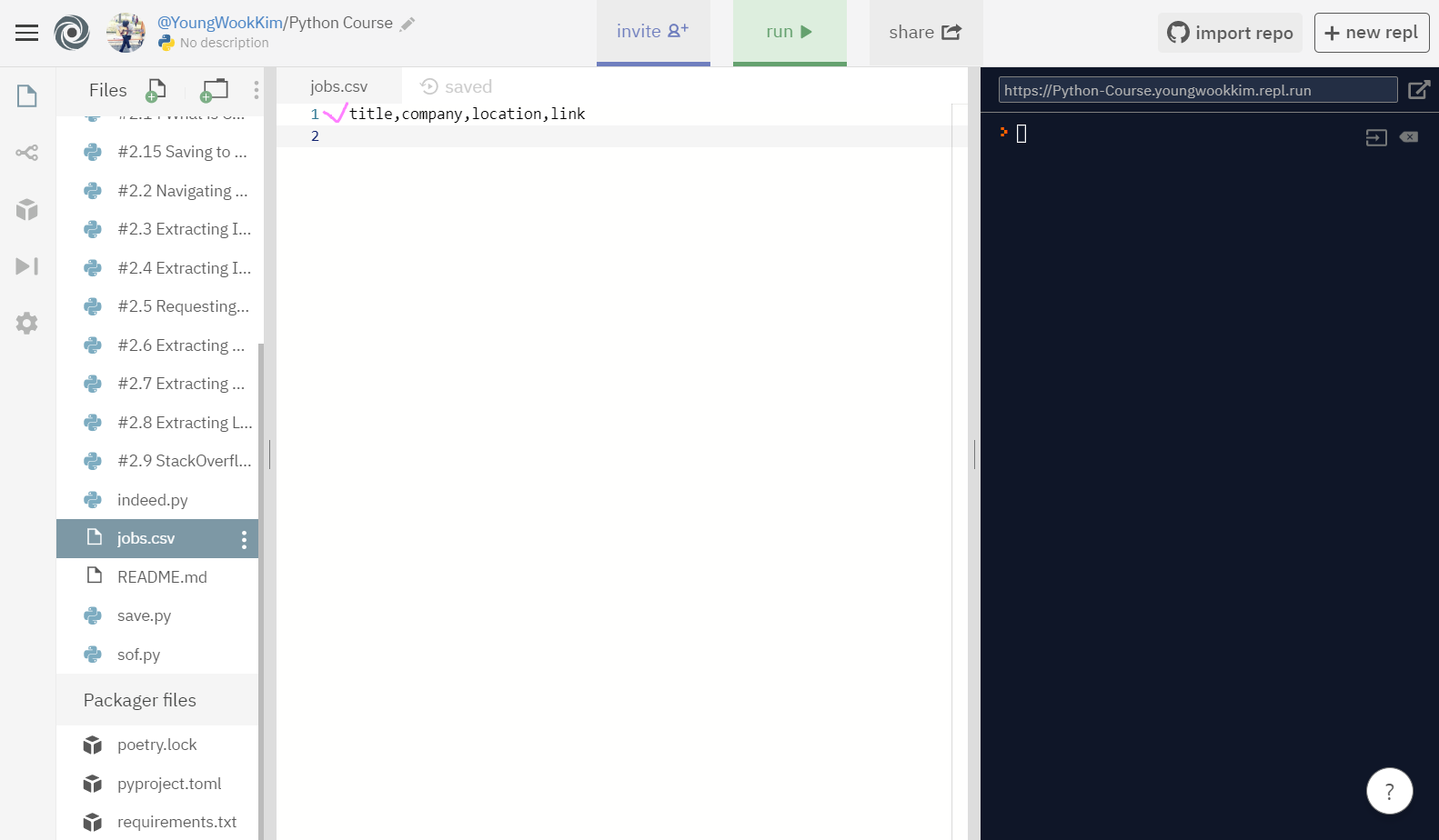
jobs.csv의 첫번째 행을 채웠다!!
3. Web Scraping한 내용으로 csv 채우기
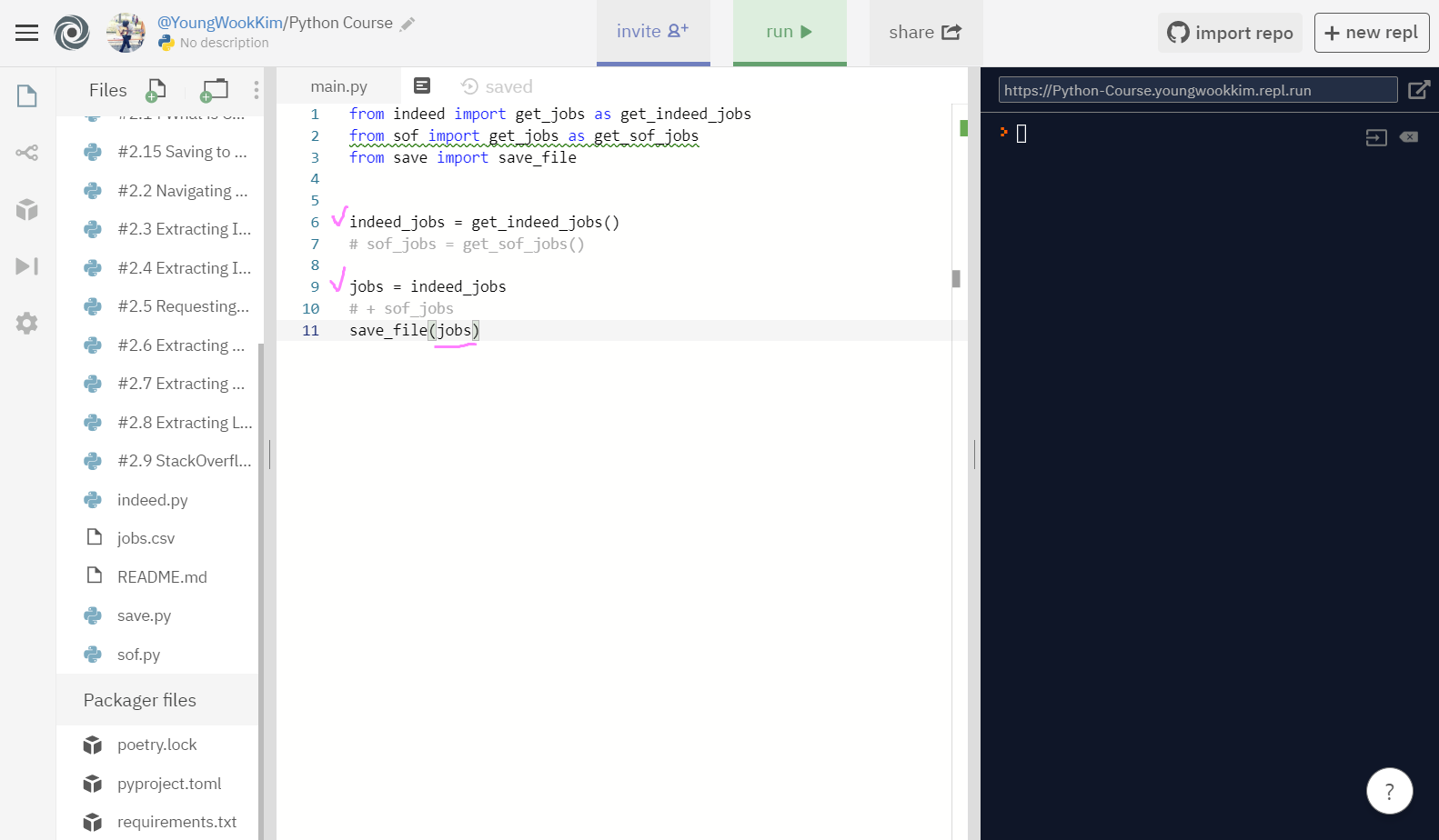
본격적으로 indeed_jobs로 추출한 정보를 csv파일로 써보겠다. (sof는 페이지가 너무 많다.. 172페이지..)
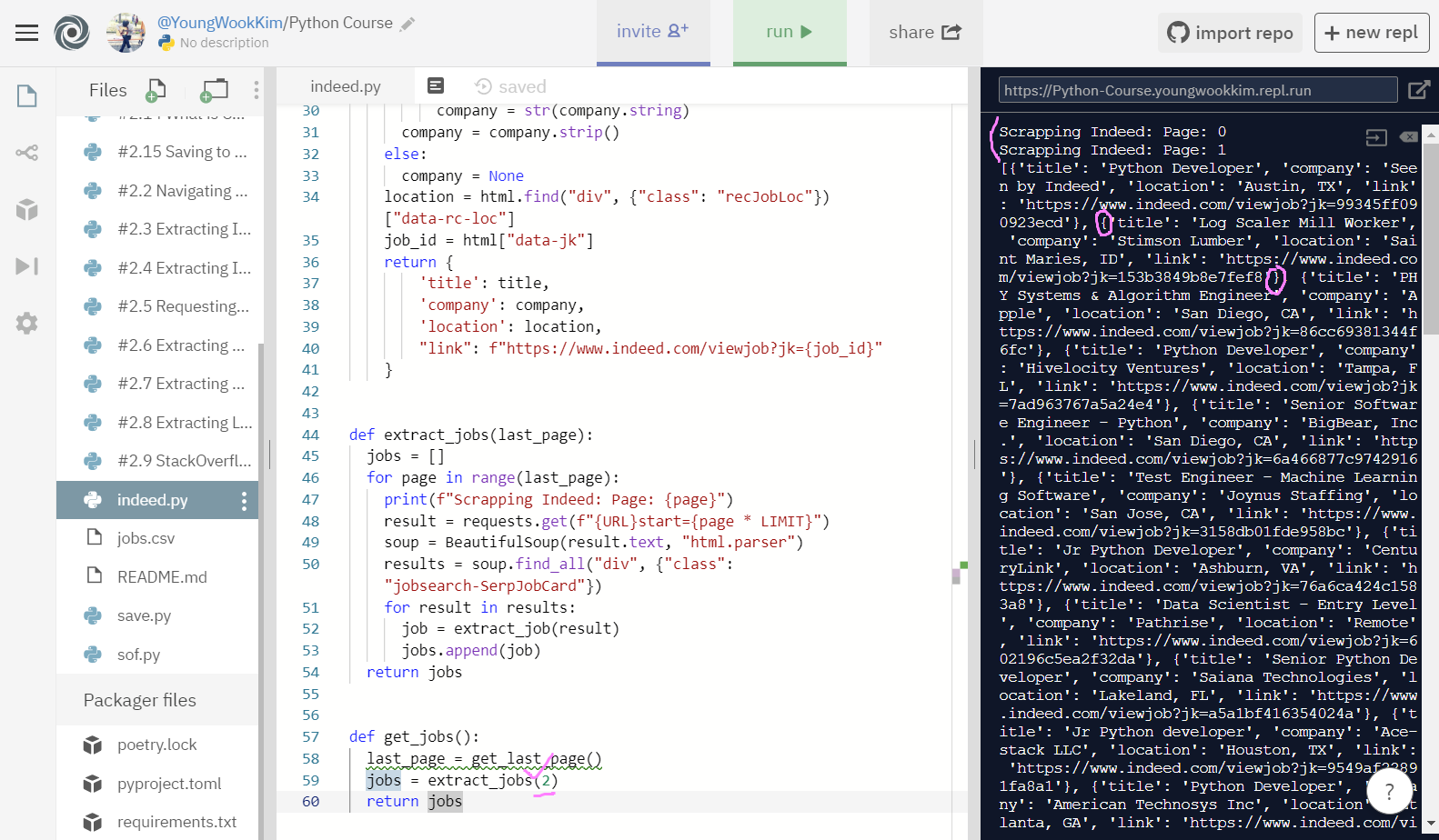
indeed에서 출력한 내용도 20page 전체를 불러오는 것이 아니라 함수를 조금 수정해줘서 2page만 불러왔다.
그리고 dictionary로 출력된 것을 알 수 있다. 이것을 이용해서 title 같은 변수명을 제외하고 변수의 values(값)만 추출할 것이다.
이것을 이용한다는 뜻은 밑에서 설명하겠다.
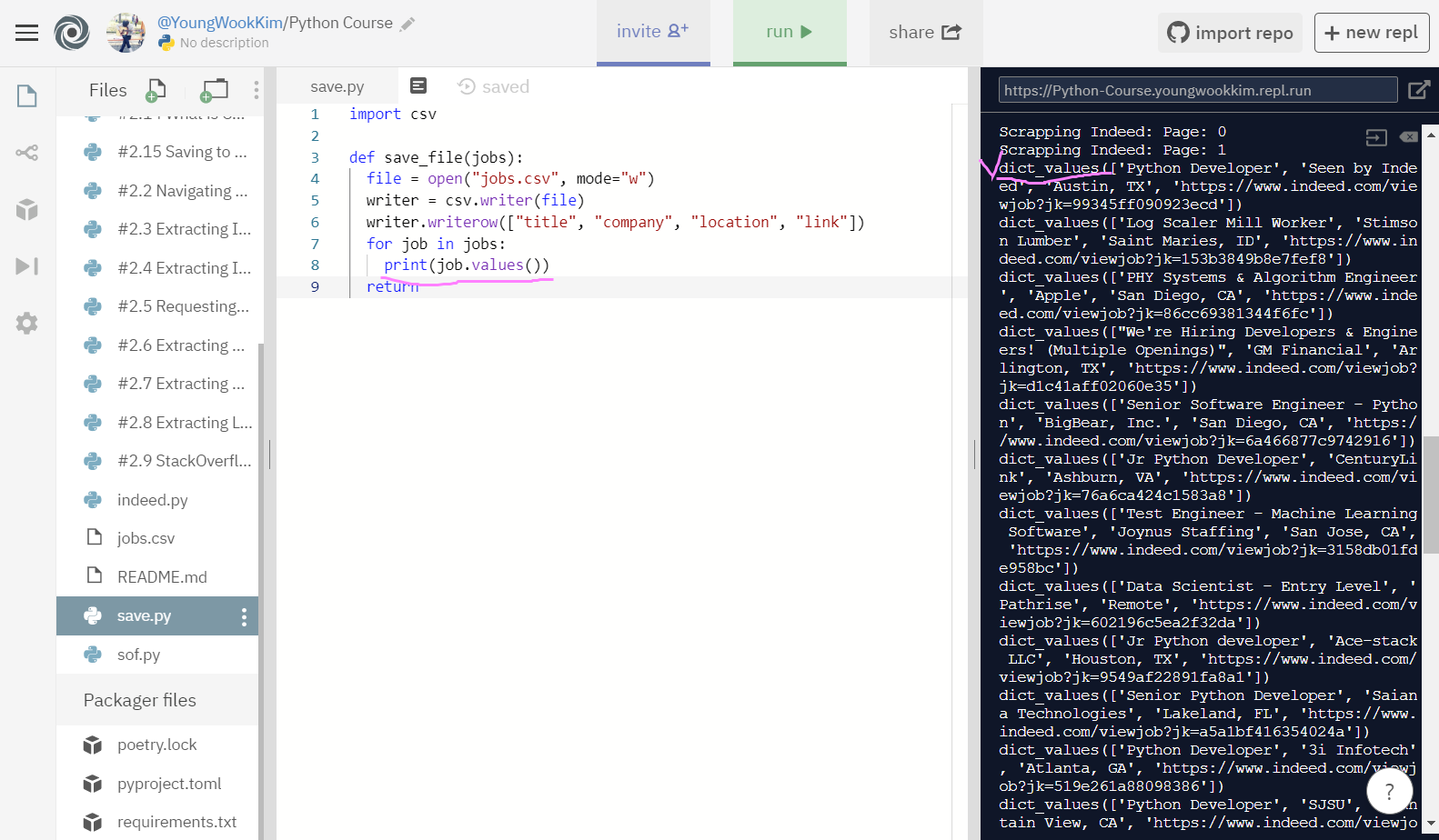
jobs = extract_jobs(2)로 indeed 2page에서 추출할 결과의, True(참)인 결과만을 계속해서(for 반복문) job.values로 변수값만 추출할 것이다.
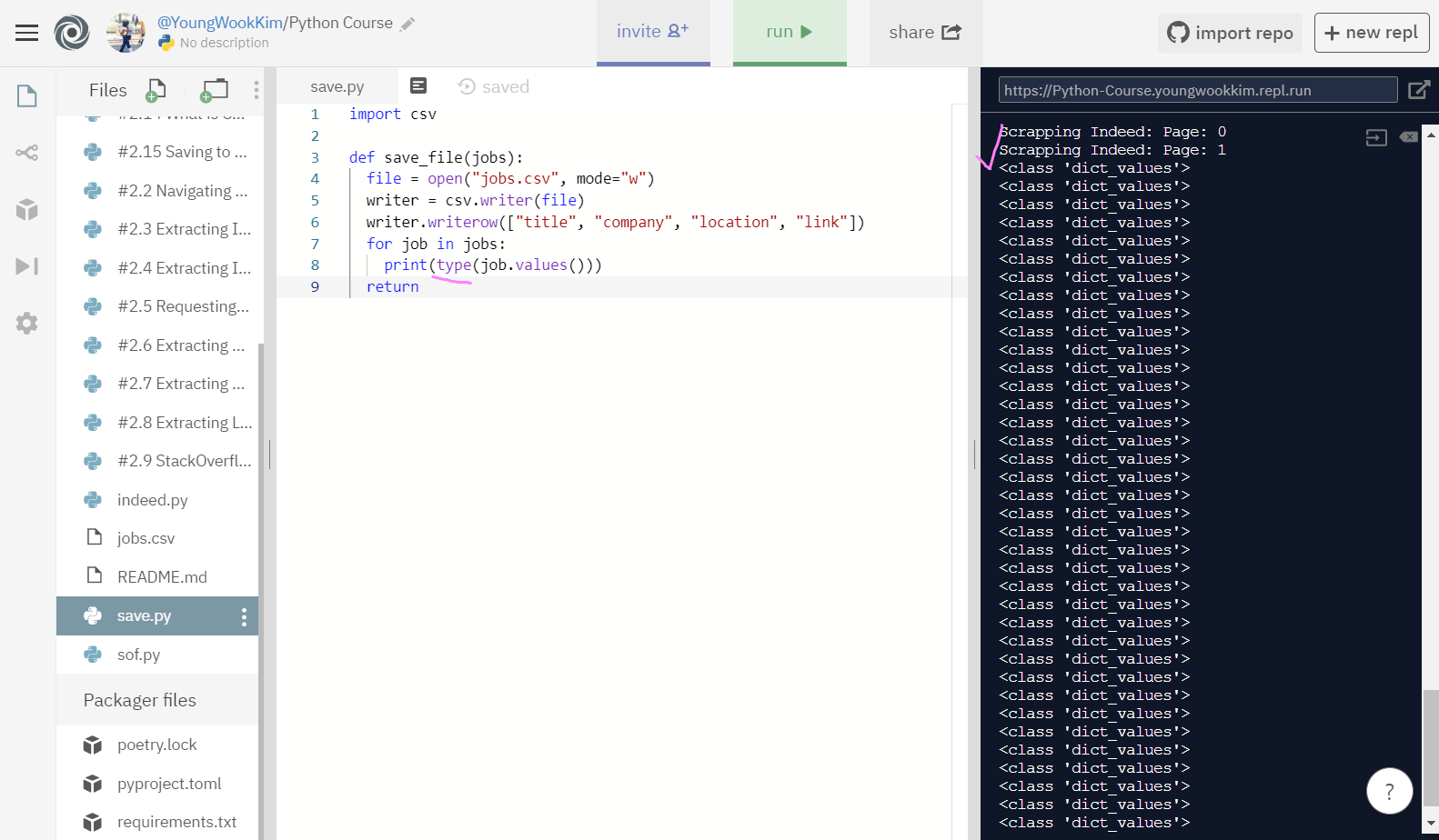
아까 이것을 이용한다고 말했는데, type을 보면 str(문자열)이 아니라 dict_values로 나오는 것을 알 수 있다.
즉 dictionary만의 기능이라고 할 수 있는데, dictionary에 저장되어있는 values는 title, company 등과 같은 변수명을 제외하고 변수명의 값(value)만 추출할 수 있다!
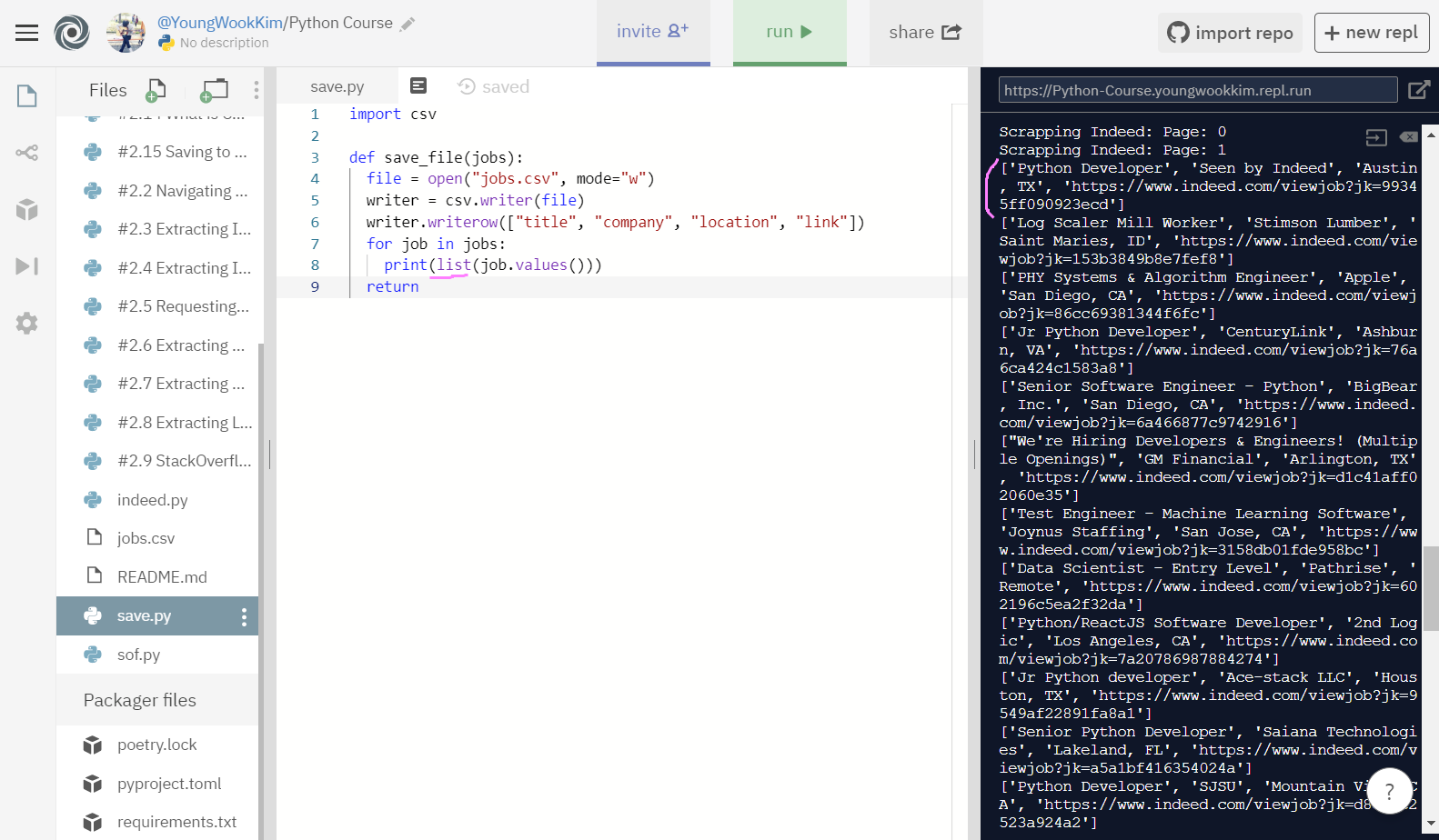
마지막으로 그 값들을 [] list로 묶어줬다.
print로 이쁘게 출력이 완료되었으니, 이제 writer.writerow로 아까처럼 행만 추가해주면 끝!!
4. 과연 성공?!
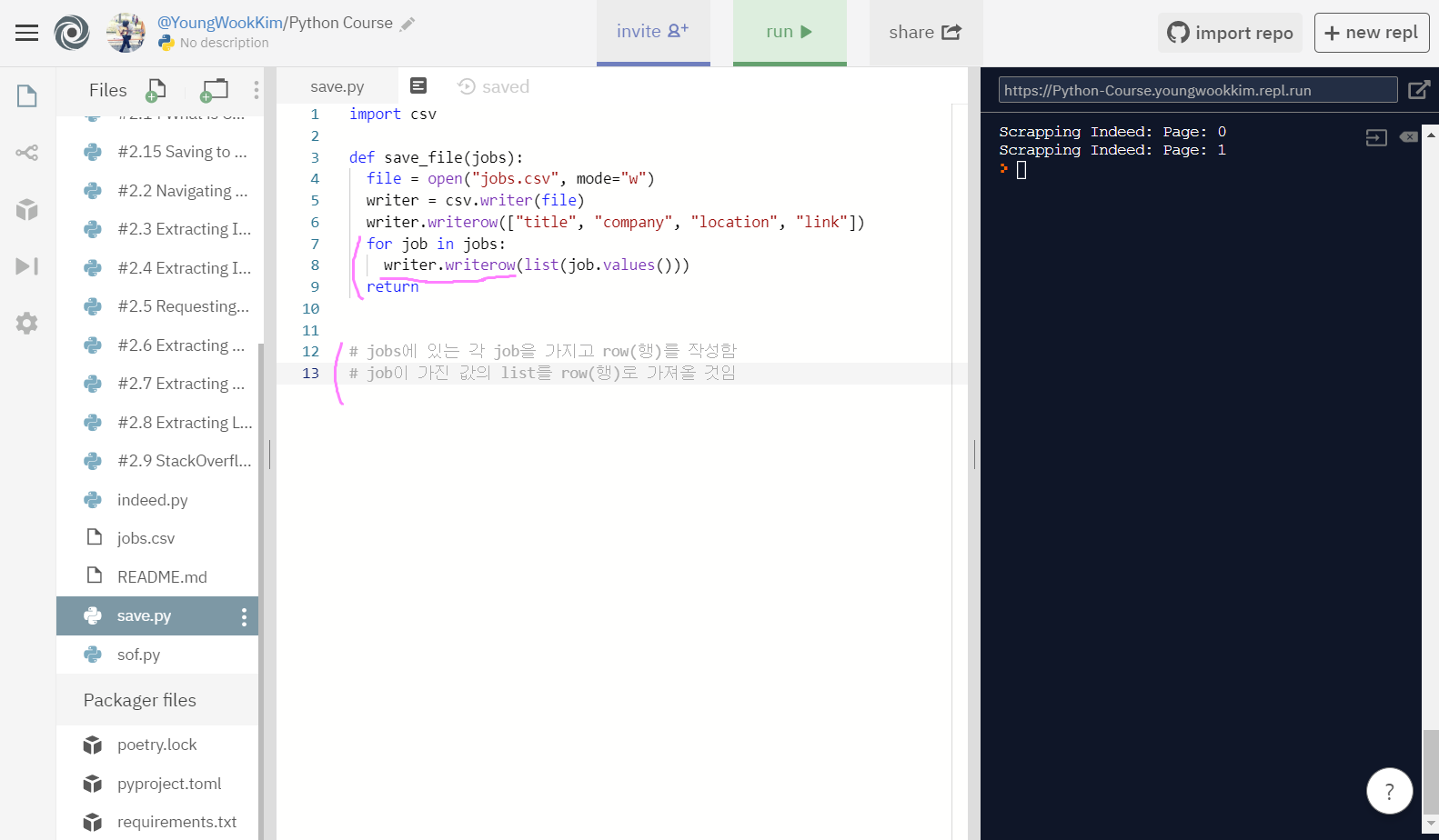
주석처리로 되어있는 내용을 보충 설명하자면, jobs는 위에서 말한 것 같이 extract_jobs(2)로 indeed 2pages를 뜻하고, 여기서 job이란 새로운 변수명을 만들어서 job.vlaues, 변수의 값만 list화 해서 row(행으로) csv파일에 write(적어라)가 된다.
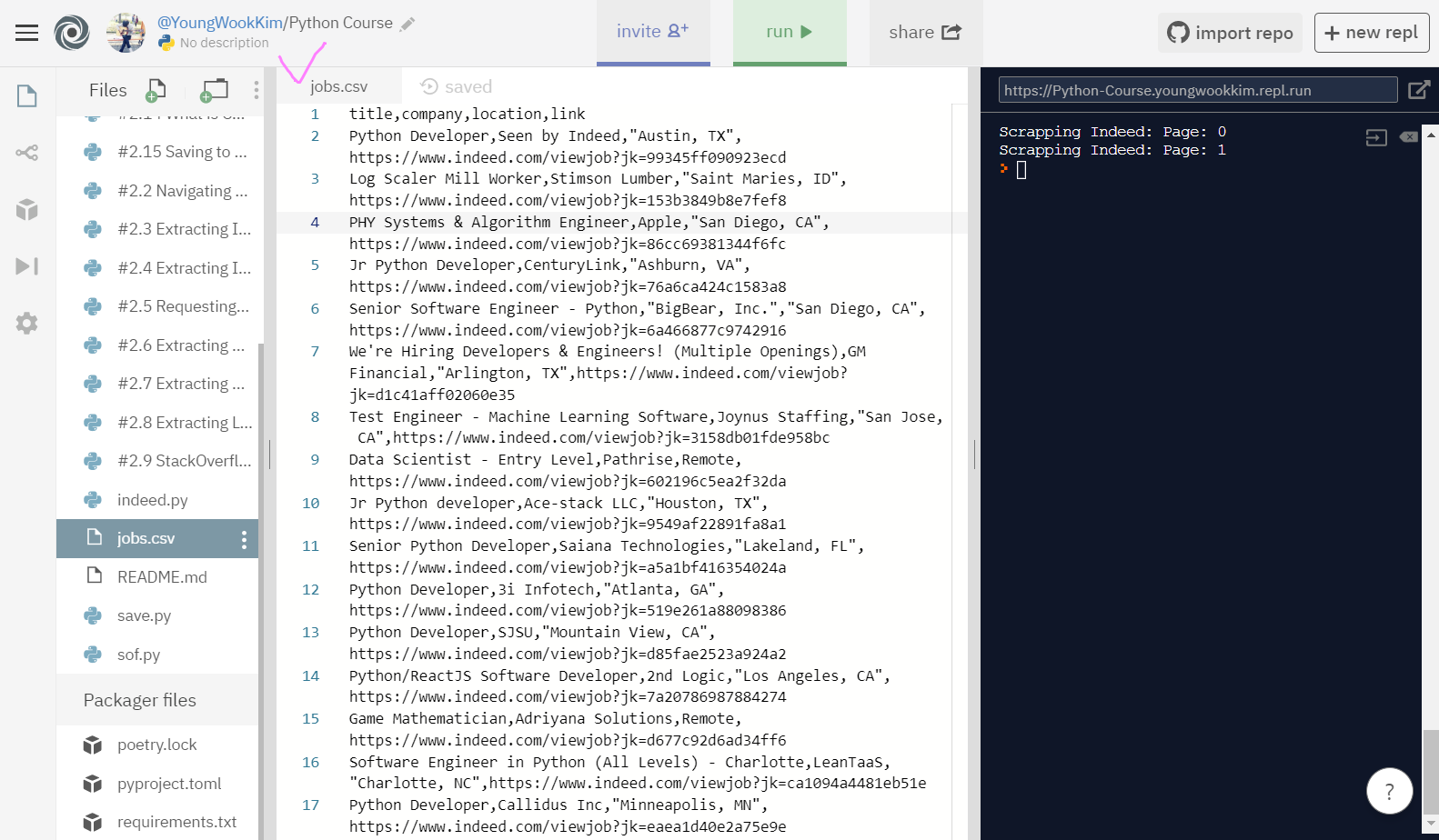
성공!! 이제 jobs.csv파일을 Google 스프레드 시트에 넣기만하면
title(1열) , company(2열), location(3열), link(4열) 순으로 정리되서 엑셀로 볼 수 있을 것이다.
<코드기록>
# main.py
from indeed import get_jobs as get_indeed_jobs
from sof import get_jobs as get_sof_jobs
from save import save_file
indeed_jobs = get_indeed_jobs()
# sof_jobs = get_sof_jobs()
jobs = indeed_jobs
# + sof_jobs
save_file(jobs)
# indeed.py
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_job(html):
title = html.find("div", {"class": "title"}).find("a")["title"]
company = html.find("span", {"class": "company"})
company_anchor = company.find("a")
if company:
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
else:
company = None
location = html.find("div", {"class": "recJobLoc"})["data-rc-loc"]
job_id = html["data-jk"]
return {
'title': title,
'company': company,
'location': location,
"link": f"https://www.indeed.com/viewjob?jk={job_id}"
}
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
print(f"Scrapping Indeed: Page: {page}")
result = requests.get(f"{URL}start={page * LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs
# save.py
import csv
def save_file(jobs):
file = open("jobs.csv", mode="w")
writer = csv.writer(file)
writer.writerow(["title", "company", "location", "link"])
for job in jobs:
writer.writerow(list(job.values()))
return
# jobs에 있는 각 job을 가지고 row(행)를 작성함
# job이 가진 값의 list를 row(행)로 가져올 것임
# Web Scrapping 끝!!!!1. jobs.csv 파일 Google 스프레드 시트로 옮기기
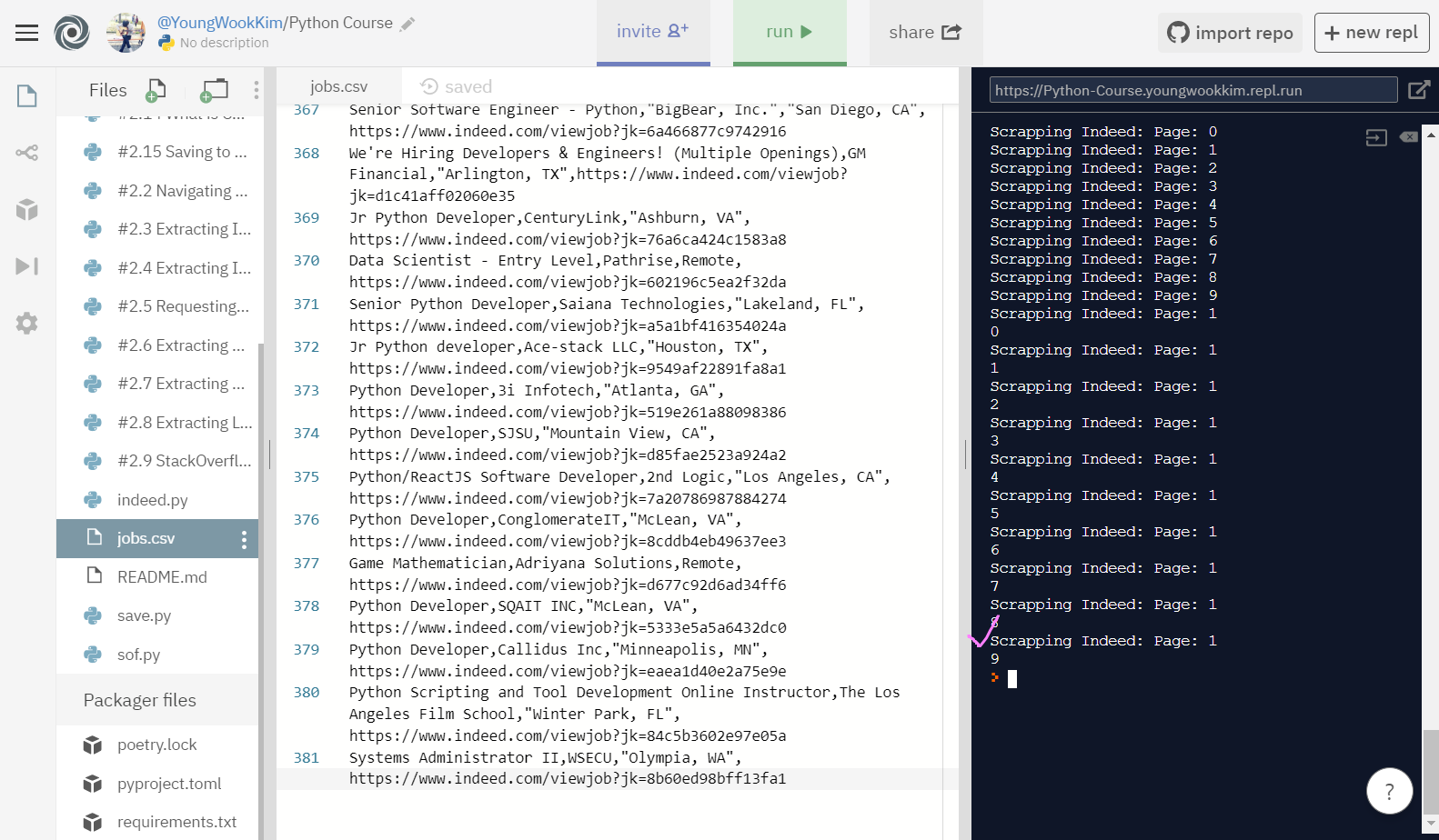
위에서는 2page까지만 추출했지만, 이번엔 indeed page 전체인 20page를 추출했다.
결과는 대성공!
Download as zip로 결과물을 다운받아서 csv파일을 컴퓨터에 저장하기!
저번에 연습했던 내용과 동일하게 왼쪽 상단의 '파일' → '업로드'로 jobs.csv파일을 올려주자.
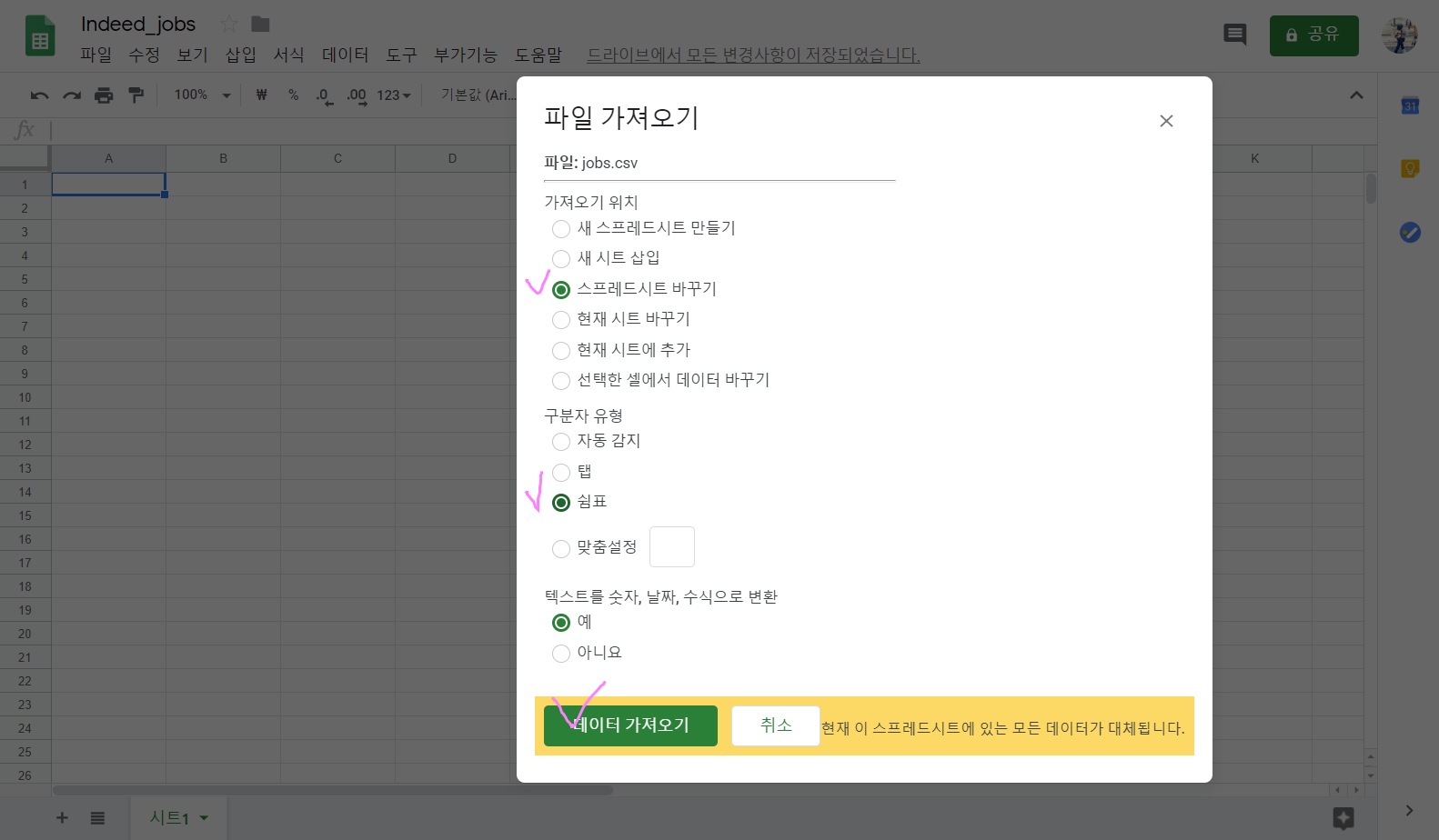
'스프레드시트 바꾸기' → '쉼표(" , " Comma)' → '예' → '데이터 가져오기'
끝!!!
2. Indeed Jobs Web Scraping!
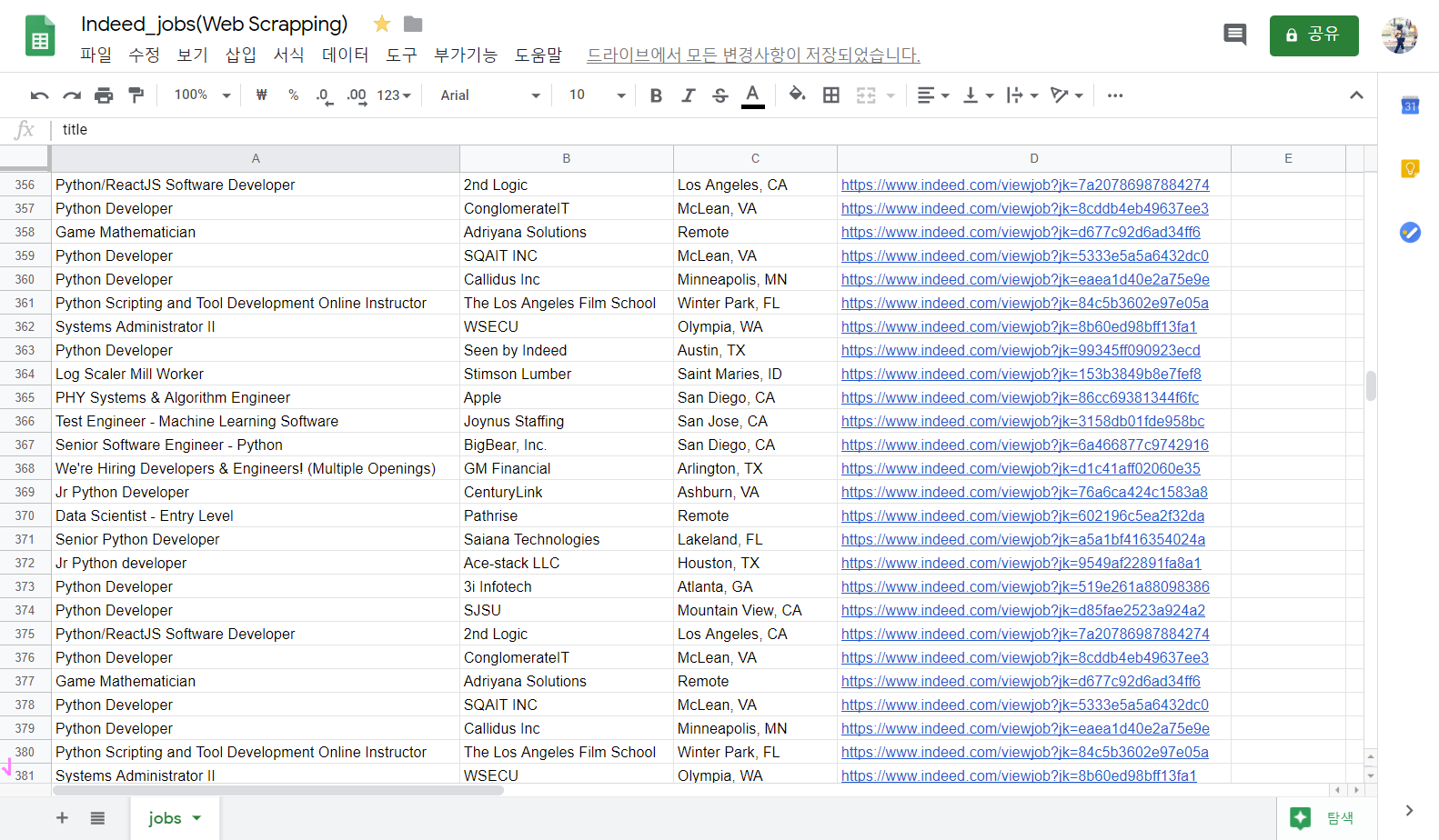
indeed 홈페이지 20page만 돌려서 381개의 직장을 저장했다.
여기서 stackoverflow 홈페이지의 172page까지 다 돌리면 3000개 직장은 훌쩍 넘길 듯하다...!!
Python으로 Web Scraping하기 끝!!! :)
※ 신종 코로나 바이러스 조심하세요!!!!

'Python > Web Scraping' 카테고리의 다른 글
| [Python] #3.2 Intro to Object Oriented Programming (#코딩공부) (0) | 2020.02.28 |
|---|---|
| [Python] #3.0 Django is AWESOME / #3.1 *args **kwargs (#코딩공부) (0) | 2020.02.27 |
| [Python] #2.14 What is CSV(Comma-separated values) (#코딩공부) (0) | 2020.02.25 |
| [Python] #2.13 StackOverflow Finish (#코딩공부) (0) | 2020.02.24 |
| [Python] #2.11 StackOverflow extract job / #2.12 part Two (#코딩공부) (0) | 2020.02.23 |




댓글