<복습>
https://wook-2124.tistory.com/40
[Python] #2.10 StackOverflow extract jobs (#코딩공부)
https://youtu.be/KE6_1Idtc6c <복습> https://wook-2124.tistory.com/38 [Python] #2.9 StackOverflow Pages (#코딩공부) https://youtu.be/i4RsYwp2Ln0 <복습> https://wook-2124.tistory.com/37 [Python] #2.8..
wook-2124.tistory.com
<준비물>
The world's leading online coding platform
Powerful and simple online compiler, IDE, interpreter, and REPL. Code, compile, and run code in 50+ programming languages: Clojure, Haskell, Kotlin (beta), QBasic, Forth, LOLCODE, BrainF, Emoticon, Bloop, Unlambda, JavaScript, CoffeeScript, Scheme, APL, Lu
repl.it
https://github.com/psf/requests
psf/requests
A simple, yet elegant HTTP library. Contribute to psf/requests development by creating an account on GitHub.
github.com
https://www.crummy.com/software/BeautifulSoup/
Beautiful Soup: We called him Tortoise because he taught us.
www.crummy.com
<코드기록 1>
# 오류때문에 찾은 다른분의 코딩 케이스
def extract_job(html):
title = html.find("h2", {"class":"fs-body3"}).find("a")["title"]
company, location = html.find("h3", {"class":"fs-body1"}).find_all("span", recursive=False)
company.get_text(strip=True)
location.get_text(strip=True)
job_id = html["data-jobid"]
return {"title": title, "company": company, "location": location, "link": f"https://stackoverflow.com/jobs/{job_id}"}
# 오류명: 'Tag' object cannot be interpreted as an integer
# 수정: extract_jobs >> extract_job
# 고작 s 하나 때문에 1시간을 헤맸다니....
import requests
from bs4 import BeautifulSoup
URL = f"https://stackoverflow.com/jobs?q=python&sort=i"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class":"s-pagination"}).find_all("a")
last_page = pages[-2].get_text(strip=True)
return int(last_page)
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
result = requests.get(f"{URL}&pg={page + 1}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class":"-job"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs
# title 가져오기
def extract_job(html):
title = html.find("h2", {"class":"fs-body3"}).find("a")["title"]
print(title)
# company, location 가져오기
# get_text(strip_True)를 통해서 text만 깔끔하게 가져옴.
def extract_job(html):
title = html.find("h2", {"class":"fs-body3"}).find("a")["title"]
company, location = html.find("h3", {"class":"fs-body1"}).find_all("span", recursive=False)
company.get_text(strip=True)
location.get_text(strip=True)
print(company, location)
# print(company.string, location.string)으로 str만 가져오기!
# 최종 코드
# 지금까지의 sof.py 결과물!
import requests
from bs4 import BeautifulSoup
URL = f"https://stackoverflow.com/jobs?q=python&sort=i"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class":"s-pagination"}).find_all("a")
last_page = pages[-2].get_text(strip=True)
return int(last_page)
def extract_job(html):
title = html.find("h2", {"class":"fs-body3"}).find("a")["title"]
company, location = html.find("h3", {"class":"fs-body1"}).find_all("span", recursive=False)
company.get_text(strip=True)
location.get_text(strip=True)
print(company.string, location.string)
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
result = requests.get(f"{URL}&pg={page + 1}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class":"-job"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs1. sof title 가져오기
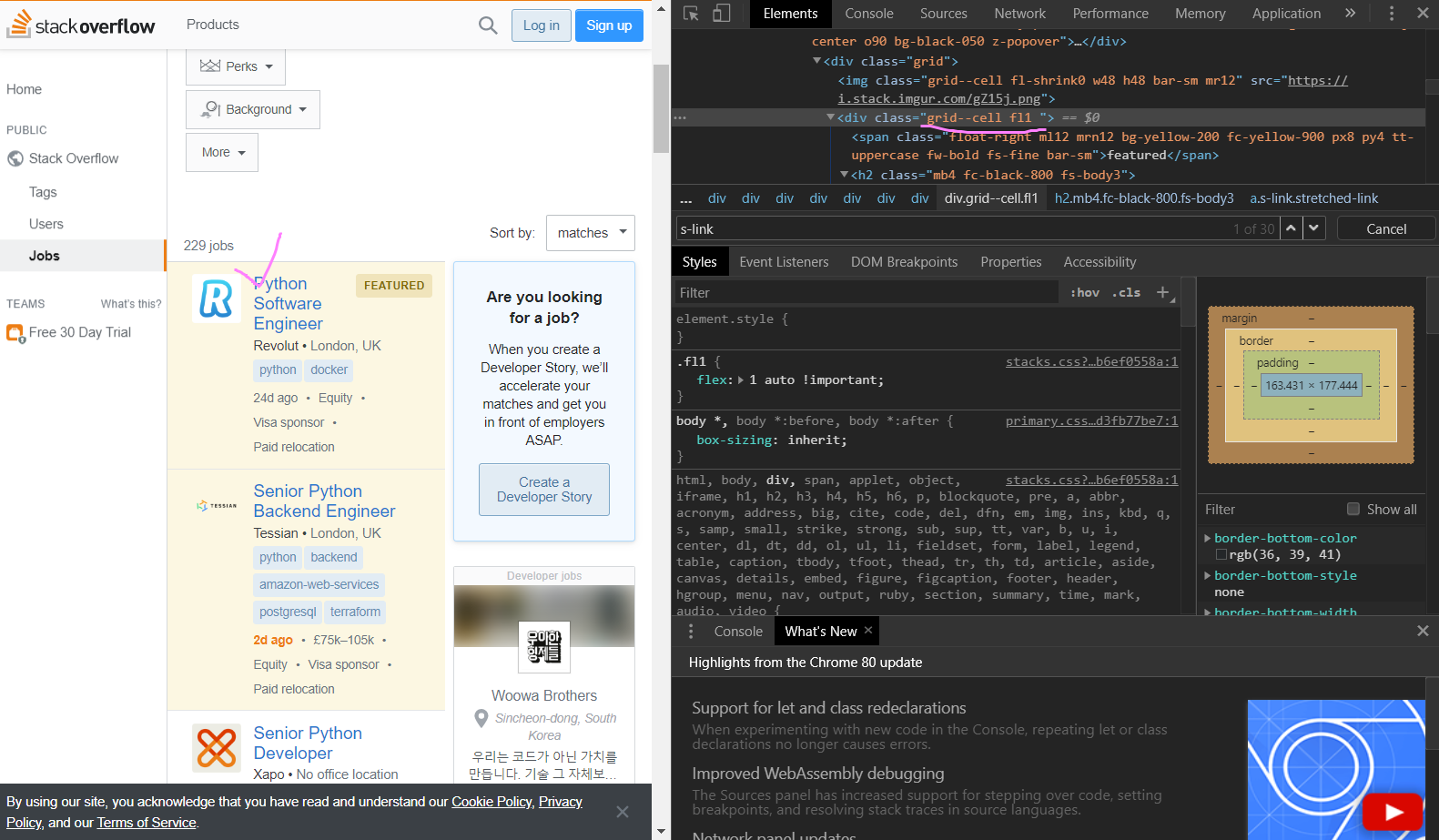
영상에서는 div class="-title"로 다소 쉬웠지만, 지금은 div class="grid--cell fl1 "으로 바뀌었다.
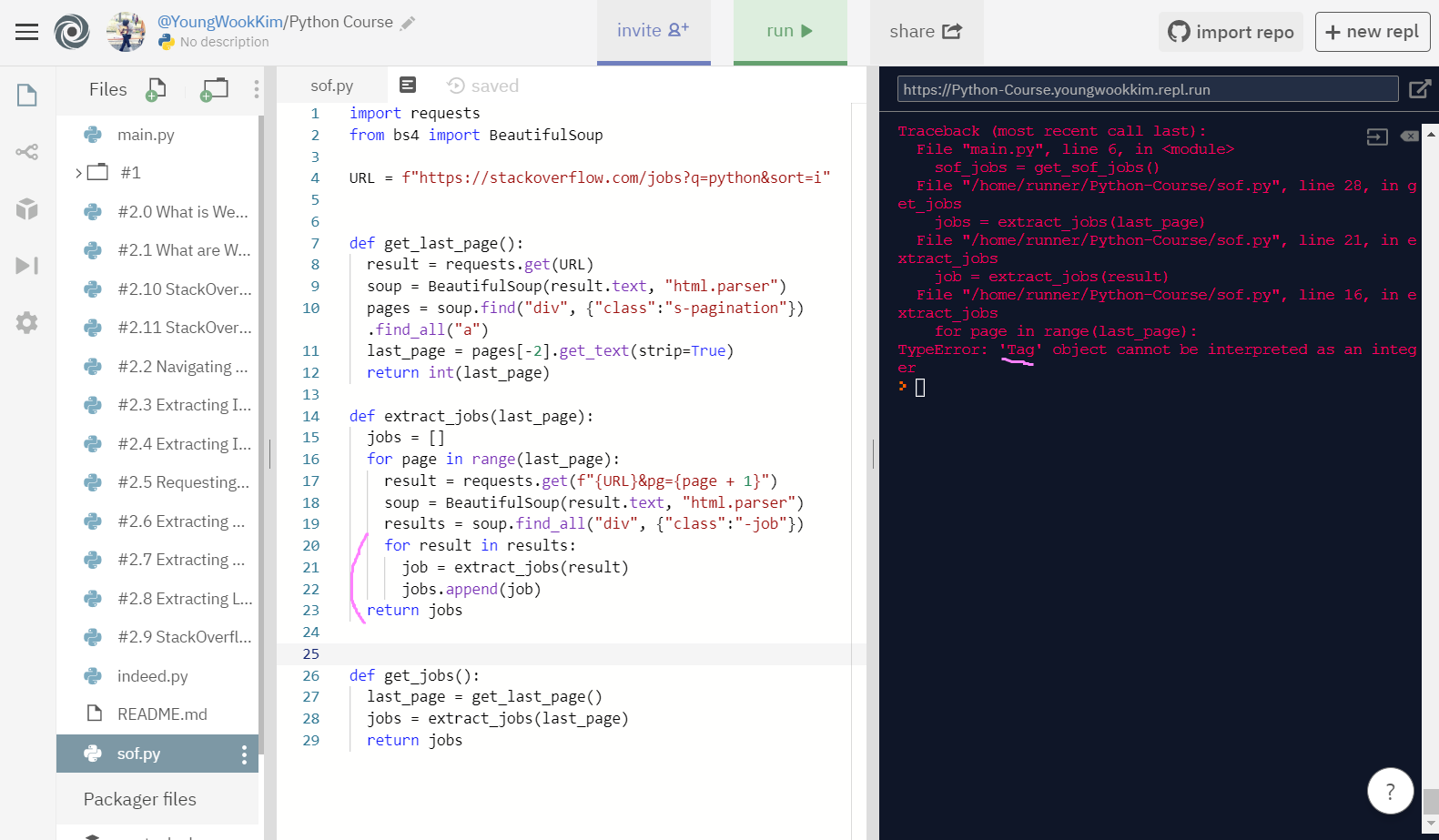
하지만 'Tag' object cannot be interpreted as an integer 오류가 떴다..
Tag 객체가 int(정수)로써 해석될 수 없다.
한 30분정도 헤매다가 답답해서 강의 댓글에서 다른 분들이 작성해둔 코드를 참고해봤다.
# 오류때문에 찾은 다른분의 코딩 케이스
def extract_job(html):
title = html.find("h2", {"class":"fs-body3"}).find("a")["title"]
company, location = html.find("h3", {"class":"fs-body1"}).find_all("span", recursive=False)
company.get_text(strip=True)
location.get_text(strip=True)
job_id = html["data-jobid"]
return {"title": title, "company": company, "location": location, "link": f"https://stackoverflow.com/jobs/{job_id}"}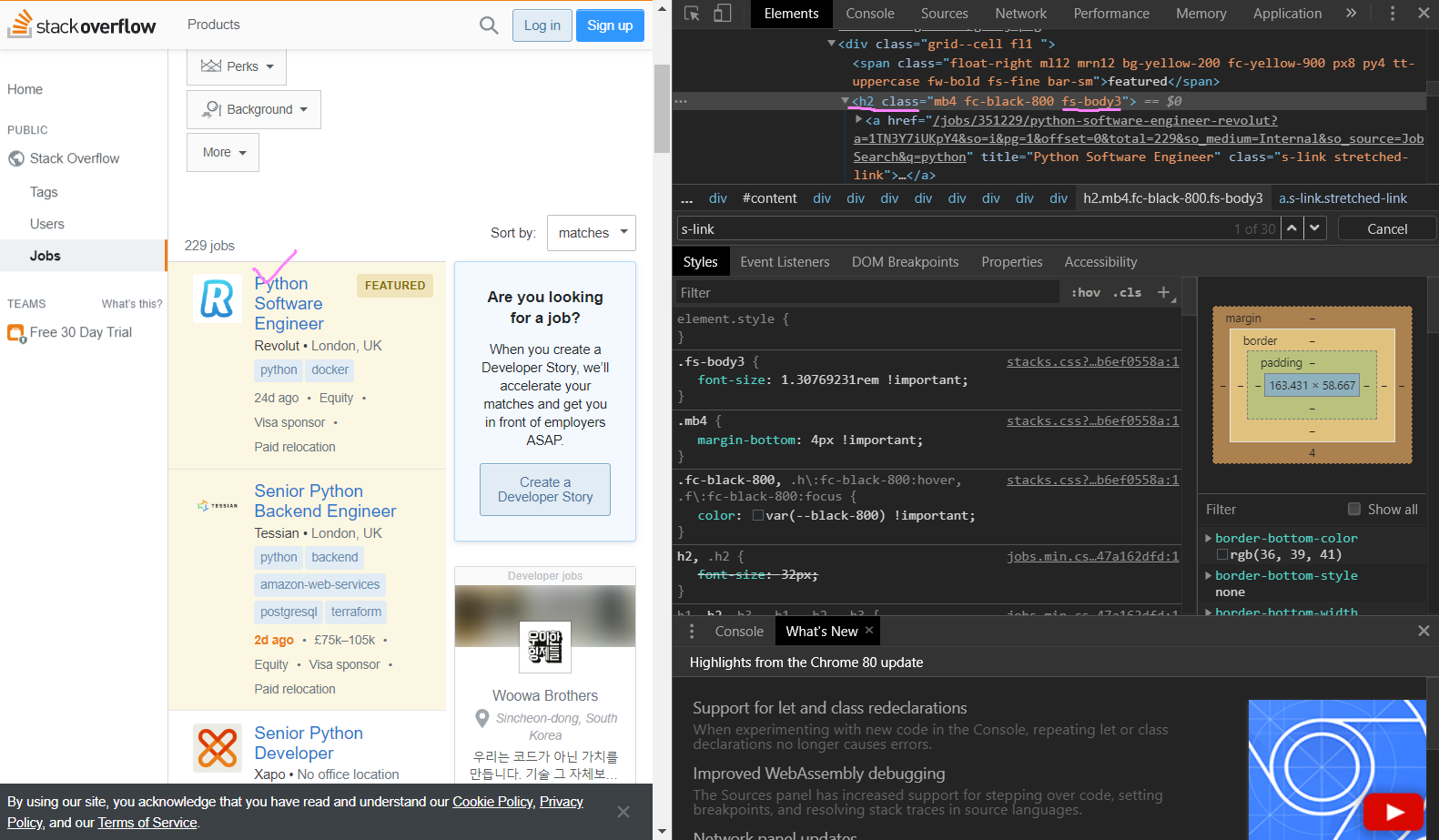
일단 title에 해당되는 div class="grid--cell fl1 " 안에 있는 h2 class="mb4 fc-black-800 fs-body3" 중 fs-body3으로 title을 추출해보기로 했다. (오류 문구 때문에 1시간 헤맸다 ㅠㅠ)
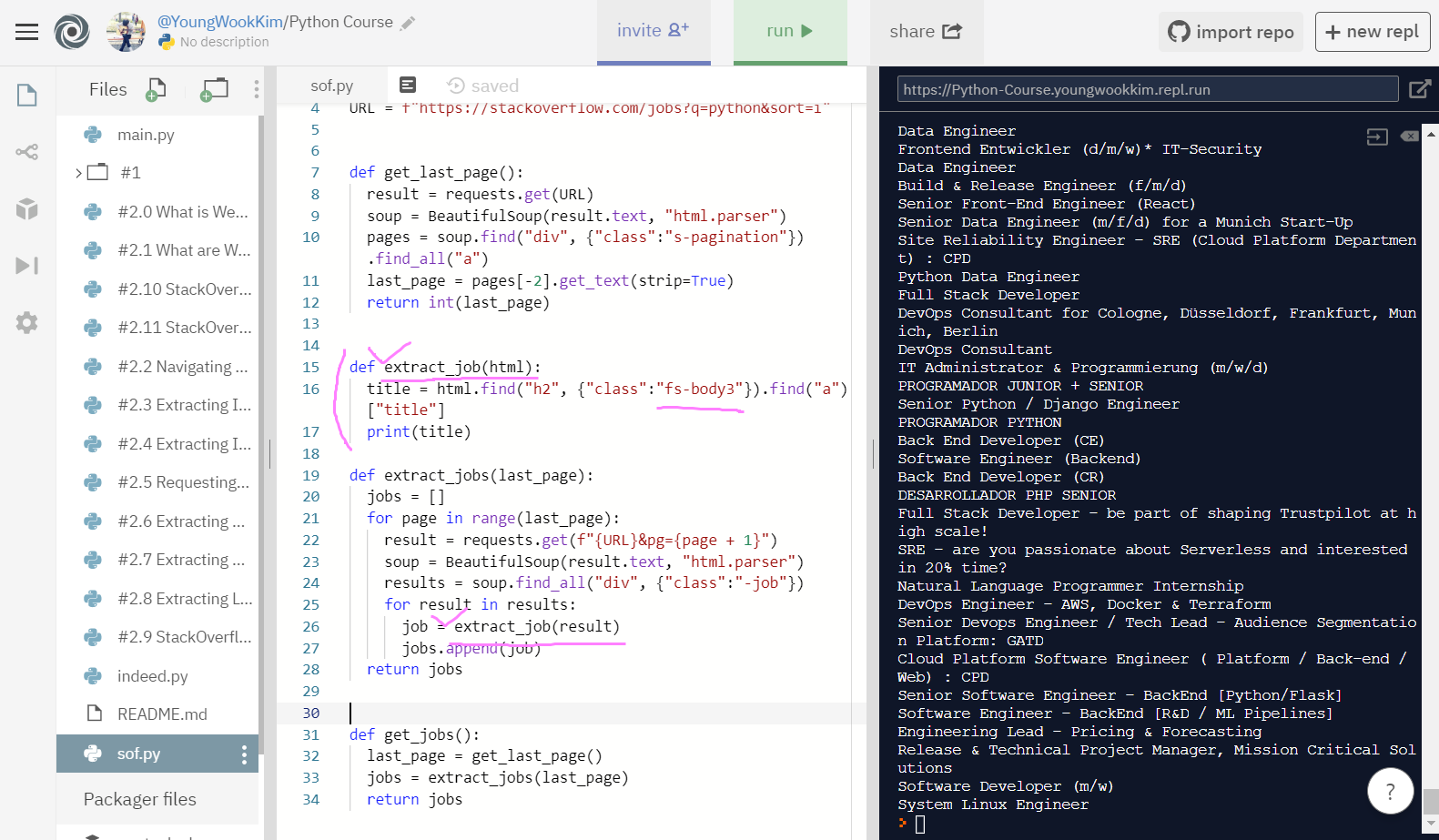
h2 class="fs-body3"로 title 출력을 하려해도 발생한 오류 'Tag' object cannot be interpreted as an integer가 없어지지 않았다.
1시간을 헤매며 다른 사람코드와 내 코드를 비교하던 중, extract_jobs(result)를 extract_job(result)로 바꾸고, def extract_jobs(html)에서 def extract_job(html)로 코드를 수정하자 제대로 출력이 됐다... ㅠㅠㅠ
이 때 Visual Studio Code 프로그램에 코드를 대입해서 빨간줄 그어진 걸 보고 수정했으면(코드가 잘 매치하는지 알아서 봐주기 때문!) 더 빠르게 오류를 찾을 수 있었을텐데, VSC에 넣지 않아 1시간을 헤맨게 아쉽다.. title 가져오기 끝!!
2. sof company와 location 가져오기
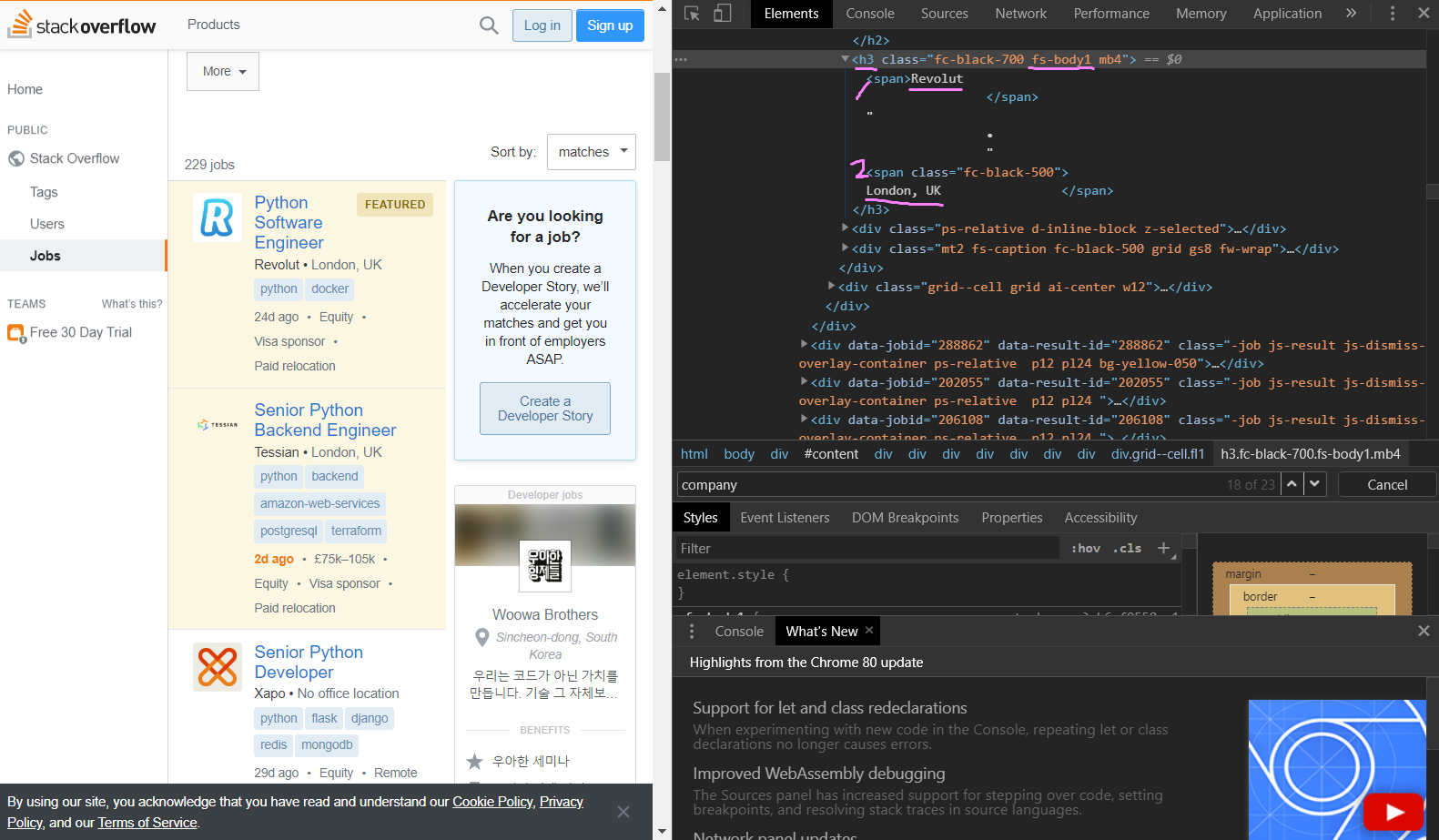
company와 location이 h3 class=" ... fs-body1.." 안 span으로 2개로 나뉘어서 들여써져있다.
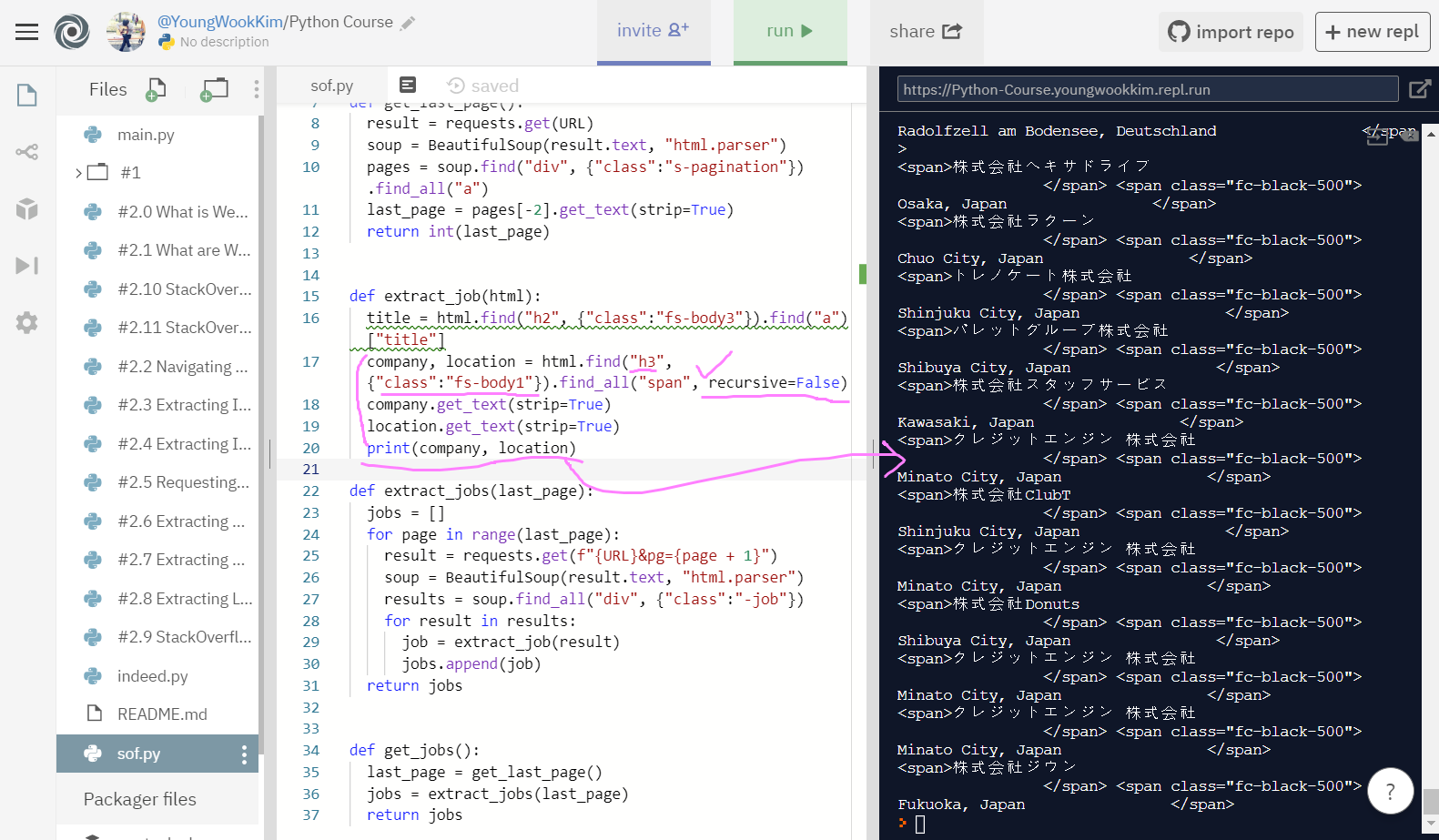
때문에 recursive=False(재귀호출 거부함수)로 코드를 써줘서 span이 2번 연속으로 나오는것을 방지했다.
그리고 [] list 안에 변수가 2개만 있는 것을 알고 있을 때는 unpacking value라고 해서 2개의 변수를 묶을 수 있다.
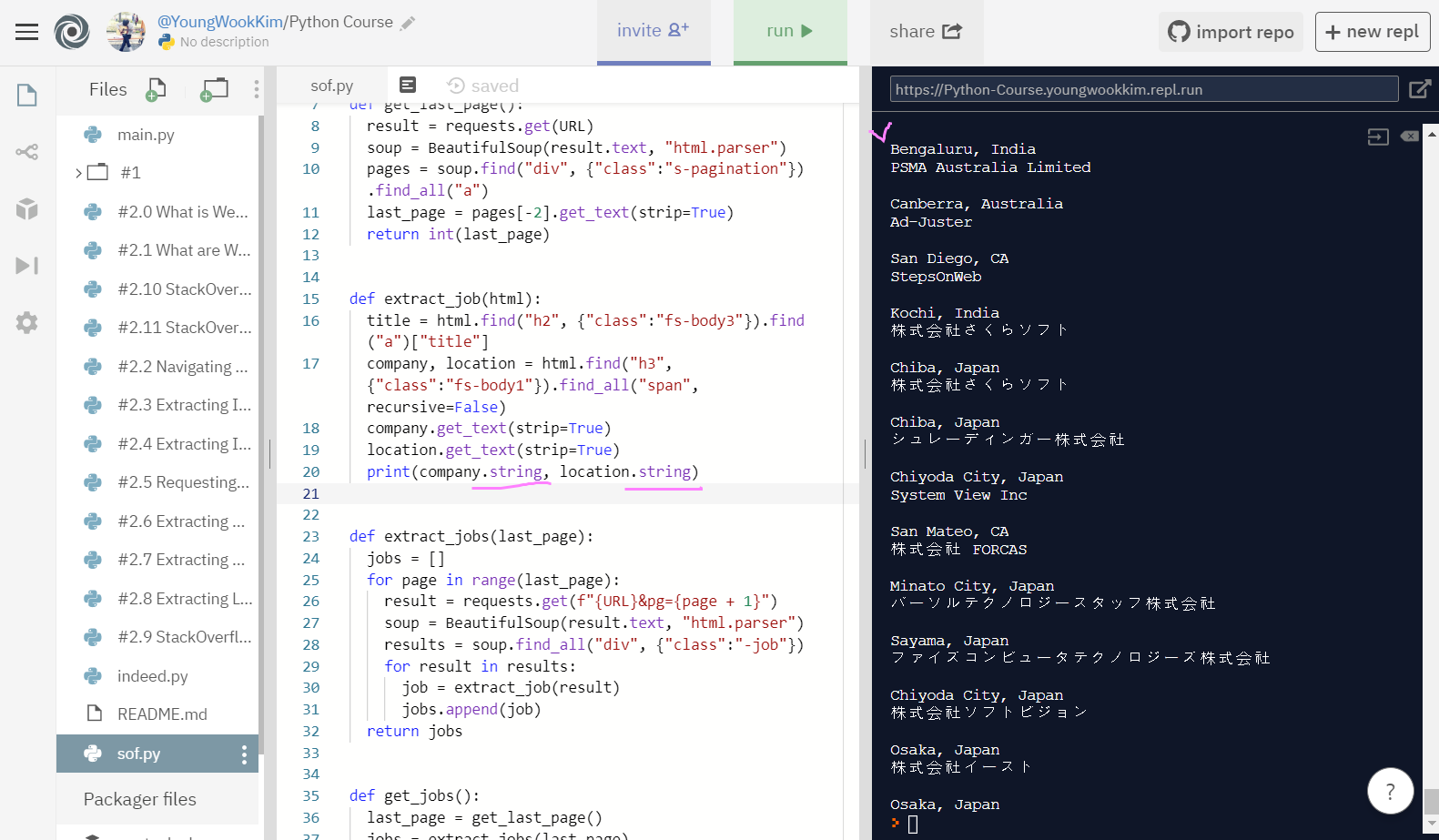
다시 말해, recursive를 False해주면 첫번째 단계의 span만 가져올 수 있고, unpacking도 할 수 있다.
그 다음 .get_text(strip=True)를 통해서 먼저 text만 나오게하고 strip=Ture로 빈칸을 없애고 .string을 통해 결과물을 string으로 정리했다.
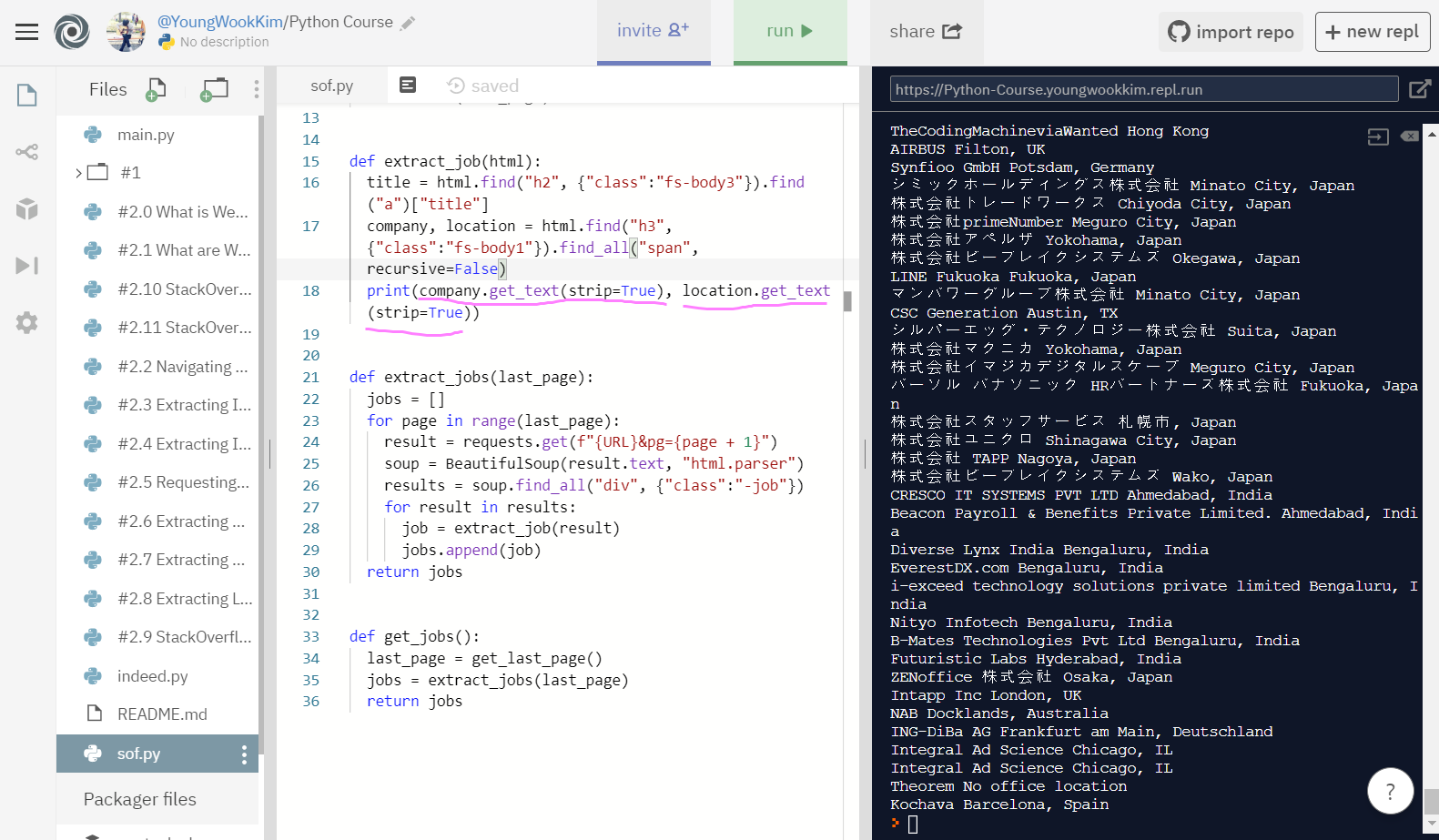
비교를 위해 .string 없이 print해본 것인데, 결과물만 봐도 .string으로 값을 string으로 변환해주고 미리 .get_text(strip=True)으로 빈칸을 없앤 뒤 print한 것이 훨씬 깔끔하다.
<코드기록 2>
# .strip("-").strip(" \r").strip("\n")을 추가해서
# 출력되는 것을 정리하고자함
# "-"는 뒤에 나오는 -를 지우고
# " \r"은 새로운 줄을 표현하는 방법
# "\n"도 " \r"처럼 새로운 줄을 표현함
# 그러나 뒤에 이런것들 추가안해도 전이랑 똑같음!
import requests
from bs4 import BeautifulSoup
URL = f"https://stackoverflow.com/jobs?q=python&sort=i"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class":"s-pagination"}).find_all("a")
last_page = pages[-2].get_text(strip=True)
return int(last_page)
def extract_job(html):
title = html.find("h2", {"class":"fs-body3"}).find("a")["title"]
company, location = html.find("h3", {"class":"fs-body1"}).find_all("span", recursive=False)
company.get_text(strip=True)
location.get_text(strip=True).strip("-").strip(" \r").strip("\n")
print(company.string, location.string)
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
result = requests.get(f"{URL}&pg={page + 1}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class":"-job"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs
# 최종 코드
# 추가표현 지우고, return값 입력해줌!
import requests
from bs4 import BeautifulSoup
URL = f"https://stackoverflow.com/jobs?q=python&sort=i"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class":"s-pagination"}).find_all("a")
last_page = pages[-2].get_text(strip=True)
return int(last_page)
def extract_job(html):
title = html.find("h2", {"class":"fs-body3"}).find("a")["title"]
company, location = html.find("h3", {"class":"fs-body1"}).find_all("span", recursive=False)
company.get_text(strip=True)
location.get_text(strip=True)
return {"title": title, "company": company, "location": location}
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
result = requests.get(f"{URL}&pg={page + 1}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class":"-job"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs3. extract_job(html) 코드 마무리하기
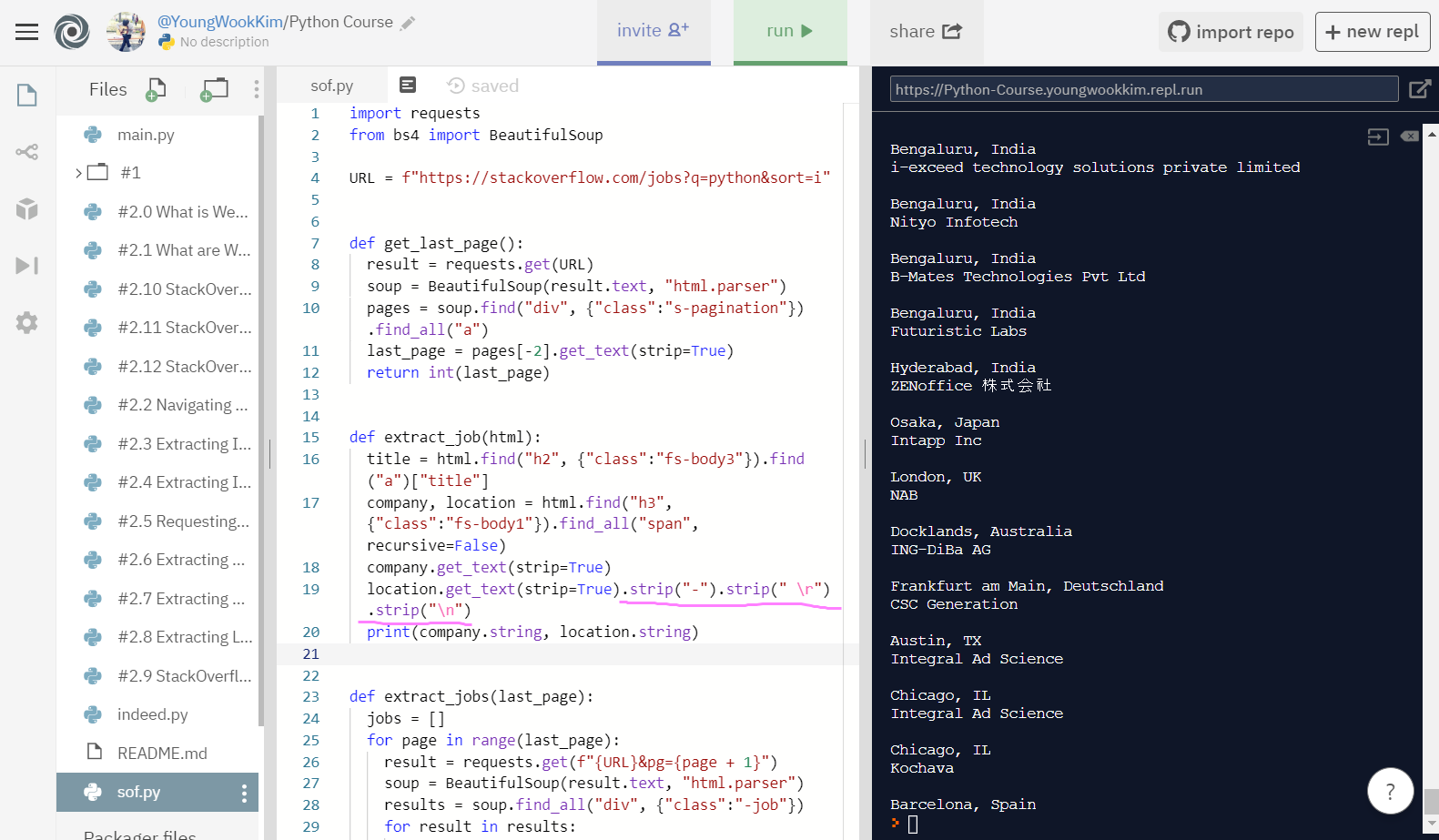
※출력물을 정리하기 위한 표현
"-" : 출력물 뒤에 나오는 -를 정리해준다.
" \r" : 새로운 줄을 표현해준다.
"\n" : 새로운 줄을 표현해준다.
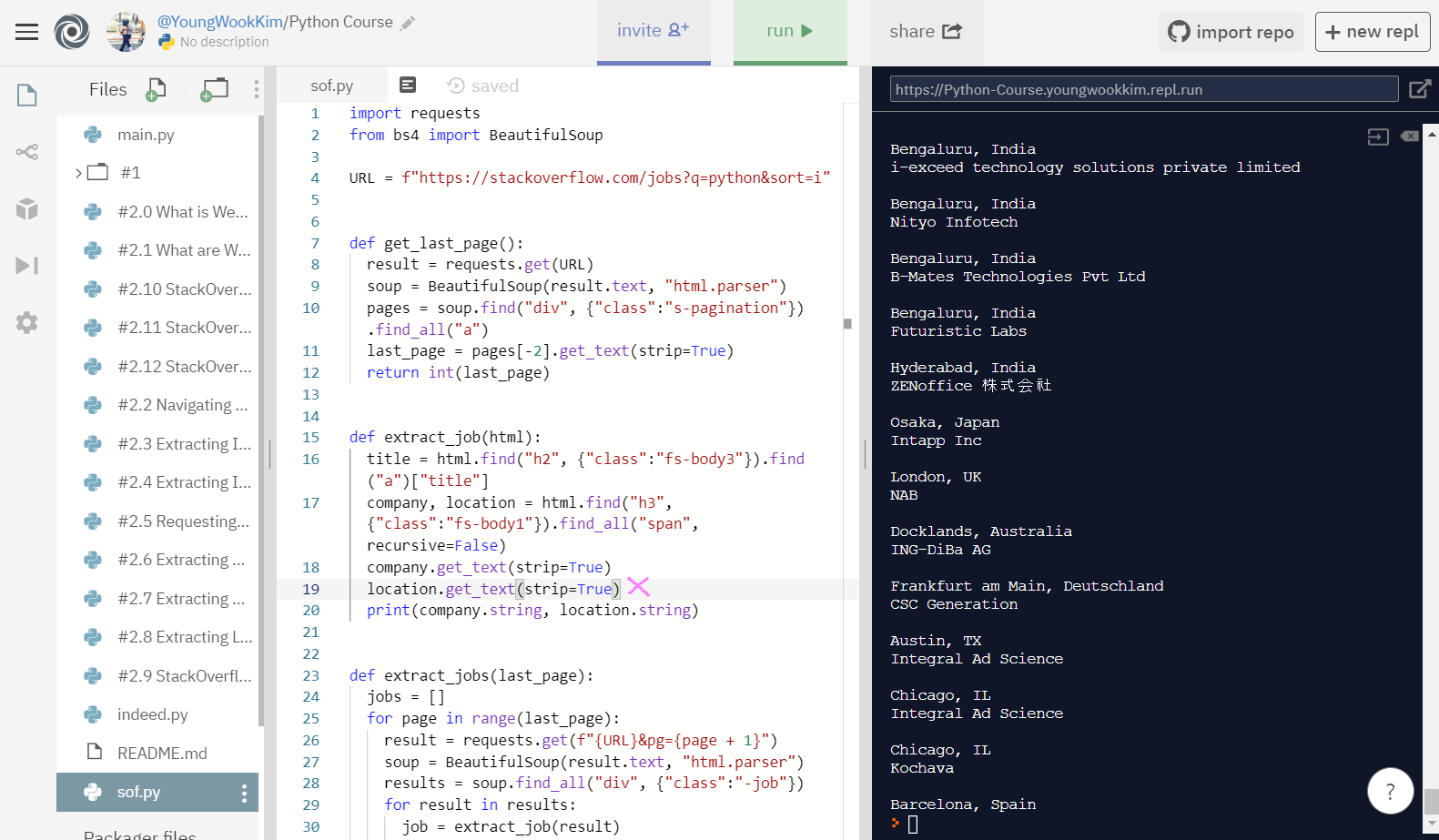
그러나 위의 표현들을 안쓰고, .get_text(strip=True), .string만으로도 깔끔하게 출력된다.
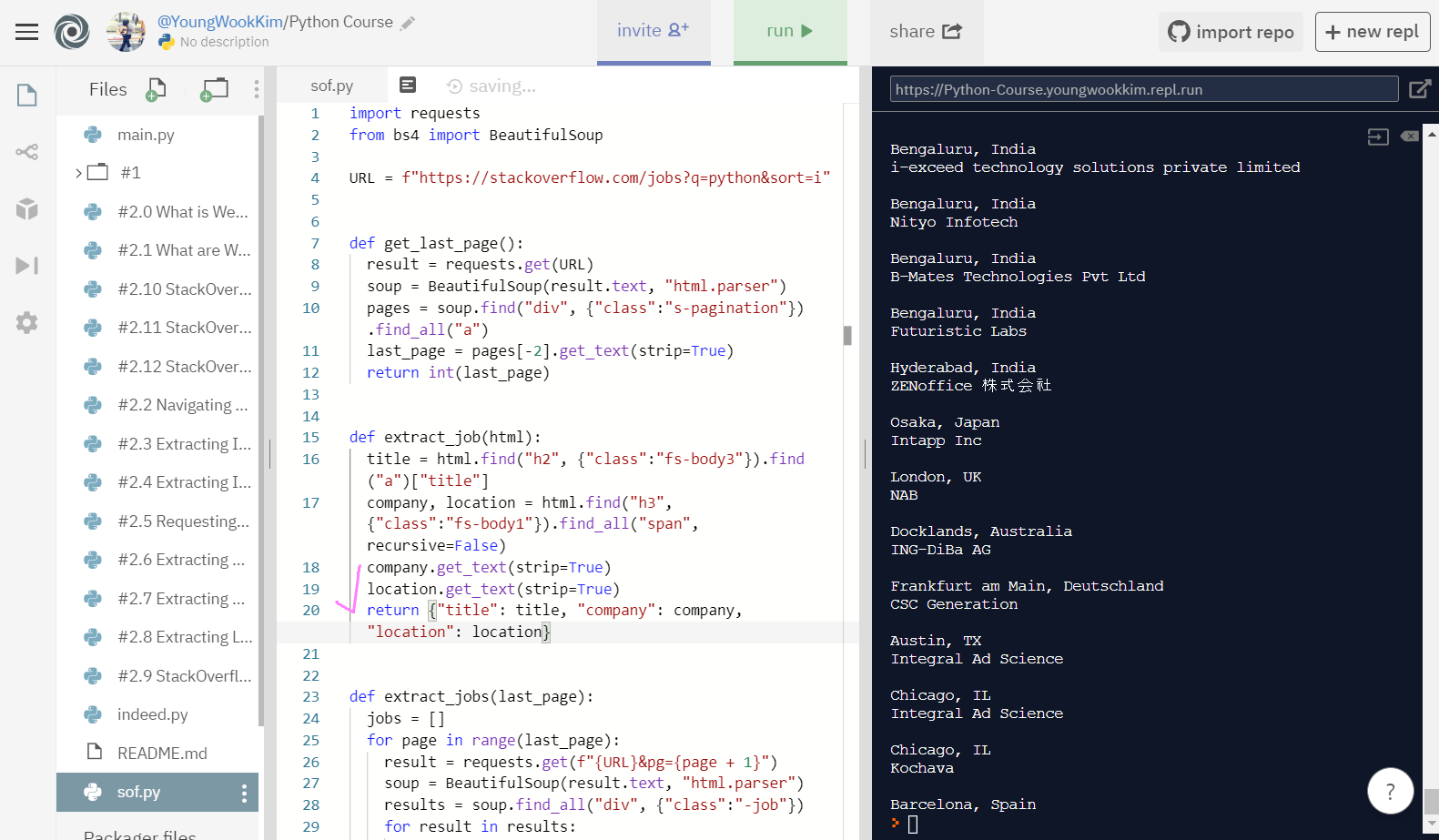
이제 지금까지 구한 title, company, location을 return 값을 돌려주고 남은 지원 URL링크만 가져오면 sof도 끝!!
※ 신종 코로나 바이러스 조심하세요!!!!

'Python > Web Scraping' 카테고리의 다른 글
| [Python] #2.14 What is CSV(Comma-separated values) (#코딩공부) (0) | 2020.02.25 |
|---|---|
| [Python] #2.13 StackOverflow Finish (#코딩공부) (0) | 2020.02.24 |
| [Python] #2.10 StackOverflow extract jobs (#코딩공부) (0) | 2020.02.22 |
| [Python] #2.9 StackOverflow Pages (#코딩공부) (0) | 2020.02.21 |
| [Python] #2.8 Extracting Locations and Finishing up (#코딩공부) (0) | 2020.02.21 |




댓글