<복습>
https://wook-2124.tistory.com/36
[Python] #2.7 Extracting Companies (#코딩공부)
https://youtu.be/tIHRPj8vbxE <복습> https://wook-2124.tistory.com/35 [Python] #2.6 Extracting Titles (#코딩공부) https://youtu.be/3vfIMmZeNNY <복습> https://wook-2124.tistory.com/31 [Python] #2.4 Ex..
wook-2124.tistory.com
<준비물>
The world's leading online coding platform
Powerful and simple online compiler, IDE, interpreter, and REPL. Code, compile, and run code in 50+ programming languages: Clojure, Haskell, Kotlin (beta), QBasic, Forth, LOLCODE, BrainF, Emoticon, Bloop, Unlambda, JavaScript, CoffeeScript, Scheme, APL, Lu
repl.it
https://github.com/psf/requests
psf/requests
A simple, yet elegant HTTP library. Contribute to psf/requests development by creating an account on GitHub.
github.com
https://www.crummy.com/software/BeautifulSoup/
Beautiful Soup: We called him Tortoise because he taught us.
www.crummy.com
<코드기록>
# extract_job(html)로 함수 간소화시키기
# 그리고 {}를 지정해서 dictionary 만들기
# title과 company 이름 따로따로 나오게끔함!
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class":"pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_job(html):
title = html.find("div", {"class":"title"}).find("a")["title"]
company = html.find("span", {"class":"company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
return {'title': title, 'company': company}
def extract_indeed_jobs(last_page):
jobs = []
# for page in range(last_page):
result = requests.get(f"{URL}start={0 * LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class":"jobsearch-SerpJobCard"})
for result in results:
job = extract_job(result)
print(job)
return jobs
# 맨 마지막 함수인 extract_indeed_jobs 수정
# job을 jobs에 append(추가)해줌
def extract_indeed_jobs(last_page):
jobs = []
# for page in range(last_page):
result = requests.get(f"{URL}start={0 * LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class":"jobsearch-SerpJobCard"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
# 중간 함수인 extract_job 수정
# location을 None이 뜨지 않게 가져오기 위해서
# display : None이 뜨기 전인 data-rc-loc까지의 정보를 출력!
def extract_job(html):
title = html.find("div", {"class":"title"}).find("a")["title"]
company = html.find("span", {"class":"company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
location = html.find("div", {"class":"recJobLoc"})["data-rc-loc"]
print(location)
return {'title': title, 'company': company, 'location': location}
# 중간 함수인 extract_job 수정
# Format Document를 통해 코드 포맷 수정하고
# ji={job_id} 인자 설정
def extract_job(html):
title = html.find("div", {"class": "title"}).find("a")["title"]
company = html.find("span", {"class": "company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
location = html.find("div", {"class": "recJobLoc"})["data-rc-loc"]
job_id = html["data-jk"]
return {
'title': title,
'company': company,
'location': location,
"link": f"https://www.indeed.com/viewjob?jk={job_id}"
}
# 마지막 함수 extract_indeed_jobs 수정
# 드디어 전체 페이지 돌리기 대작전!
# 추가로 Scrapping page {page}인자도 프린트 되게끔 수정함
# 들여쓰기 잘못해서 0페이지만 출력되었지만, 다시 제대로 고침!
def extract_indeed_jobs(last_page):
jobs = []
for page in range(last_page):
print(f"Scrapping page {page}")
result = requests.get(f"{URL}start={page * LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs1. extract_job(html)로 결과물들 모아주기
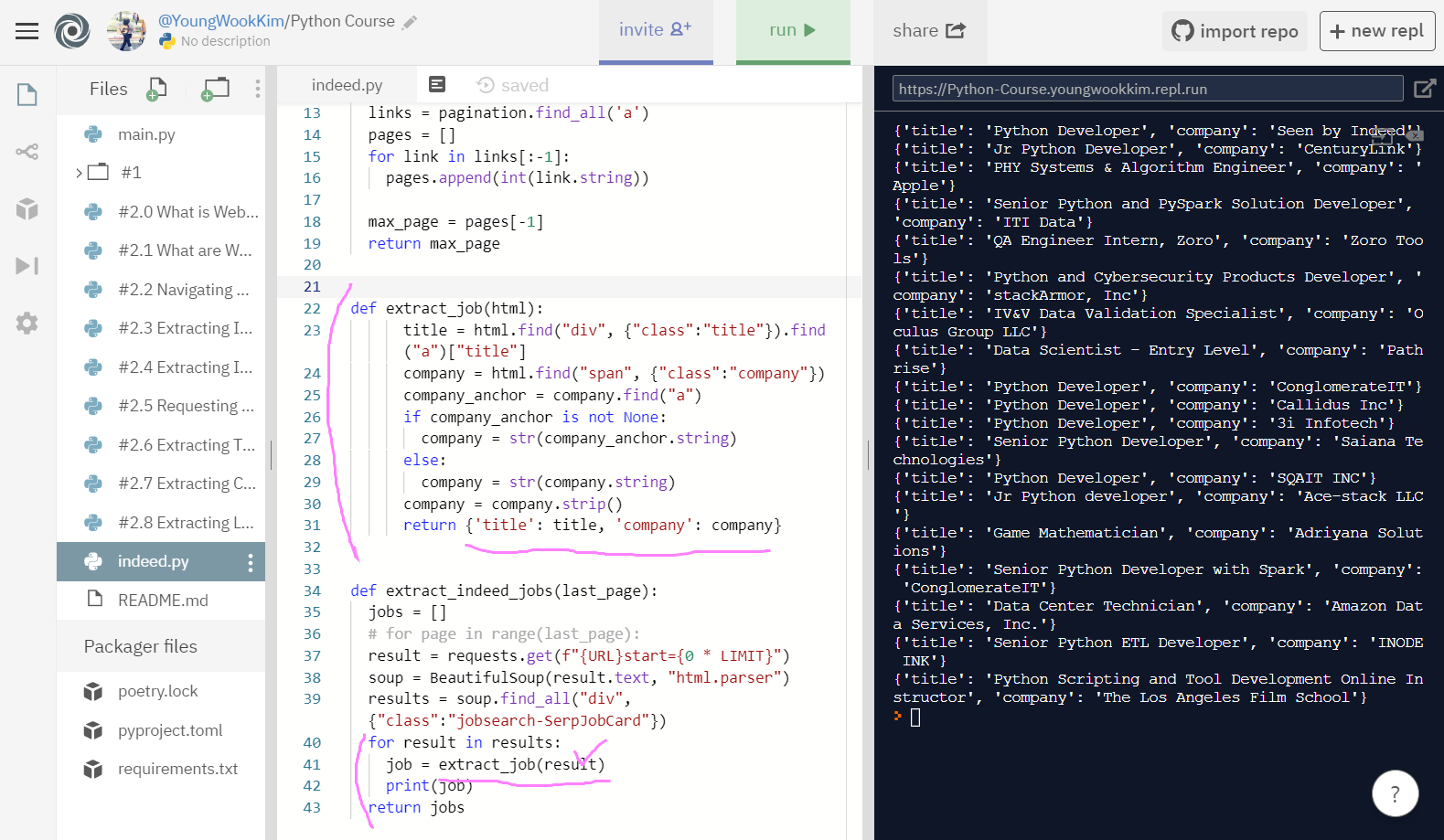
# 최종코드, title과 company 출력하기
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class":"pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_page):
jobs = []
# for page in range(last_page):
result = requests.get(f"{URL}start={0 * LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class":"jobsearch-SerpJobCard"})
for result in results:
title = result.find("div", {"class":"title"}).find("a")["title"]
company = result.find("span", {"class":"company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
print(title, company)
return jobs저번 시간에 끝냈던 title과 company 결과를 extract_job 함수에 넣어서 묶어주고 {}로 title과 company를 dictionary에 return해서 포함시킨 뒤, 사진 가장 밑에 있는 def extract_indeed_jobs으로 출력해준 값!
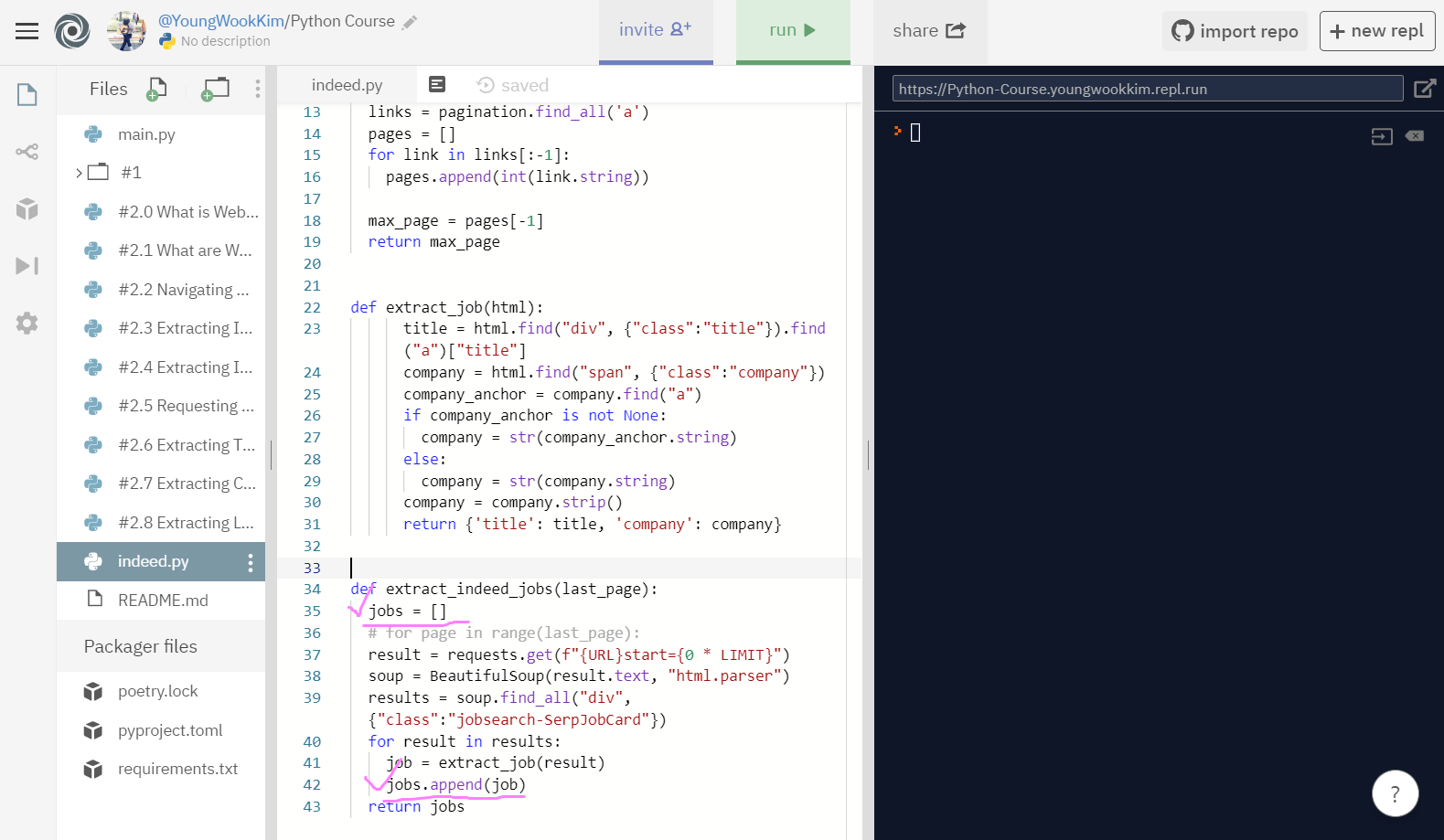
job = extract_job(result)를 jobs의 [] list/array 배열에 append(추가)해줌!
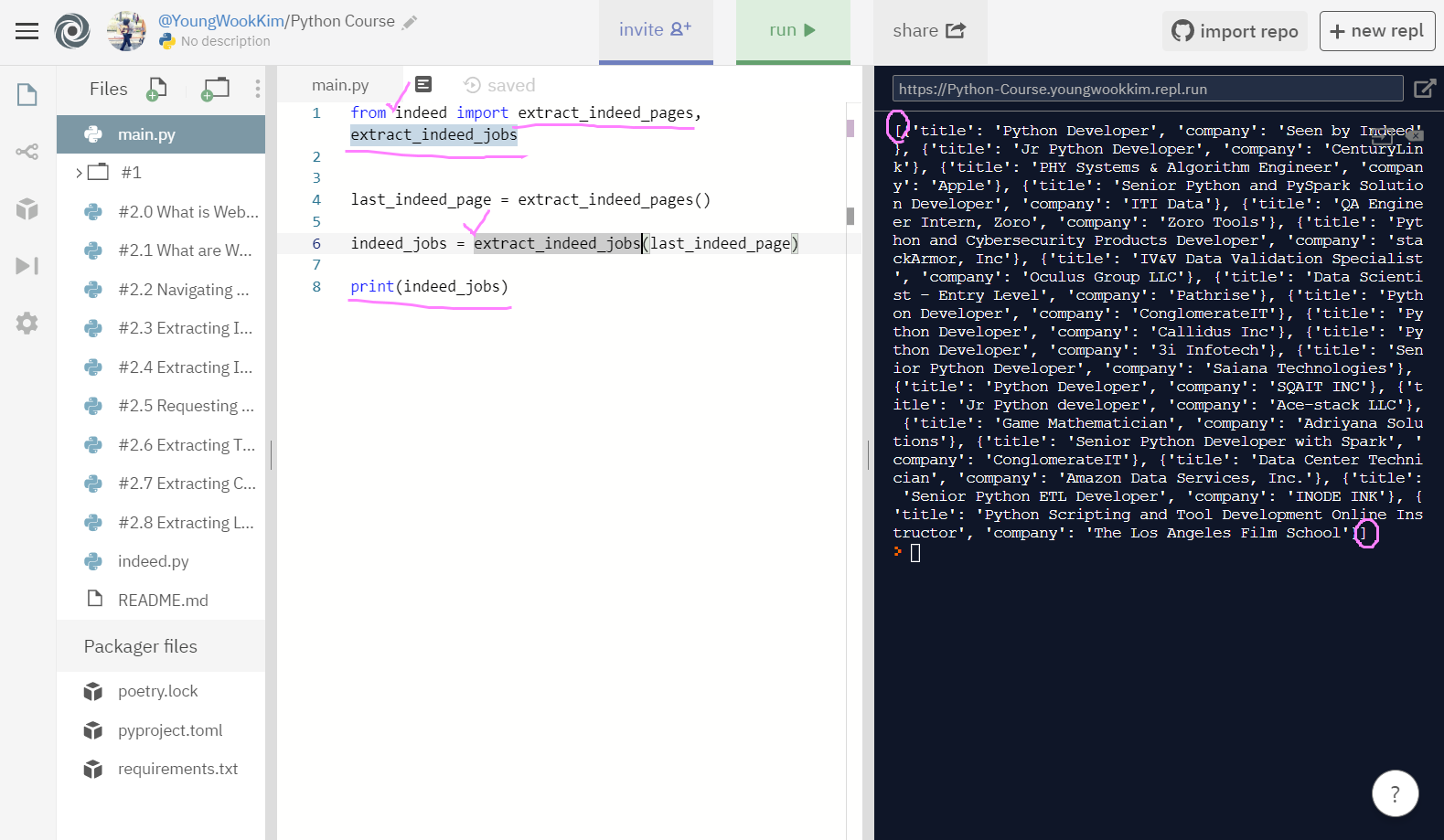
main.py에서 []로 묶여서 출력된 것을 볼 수 있다.
2. location 가져오기
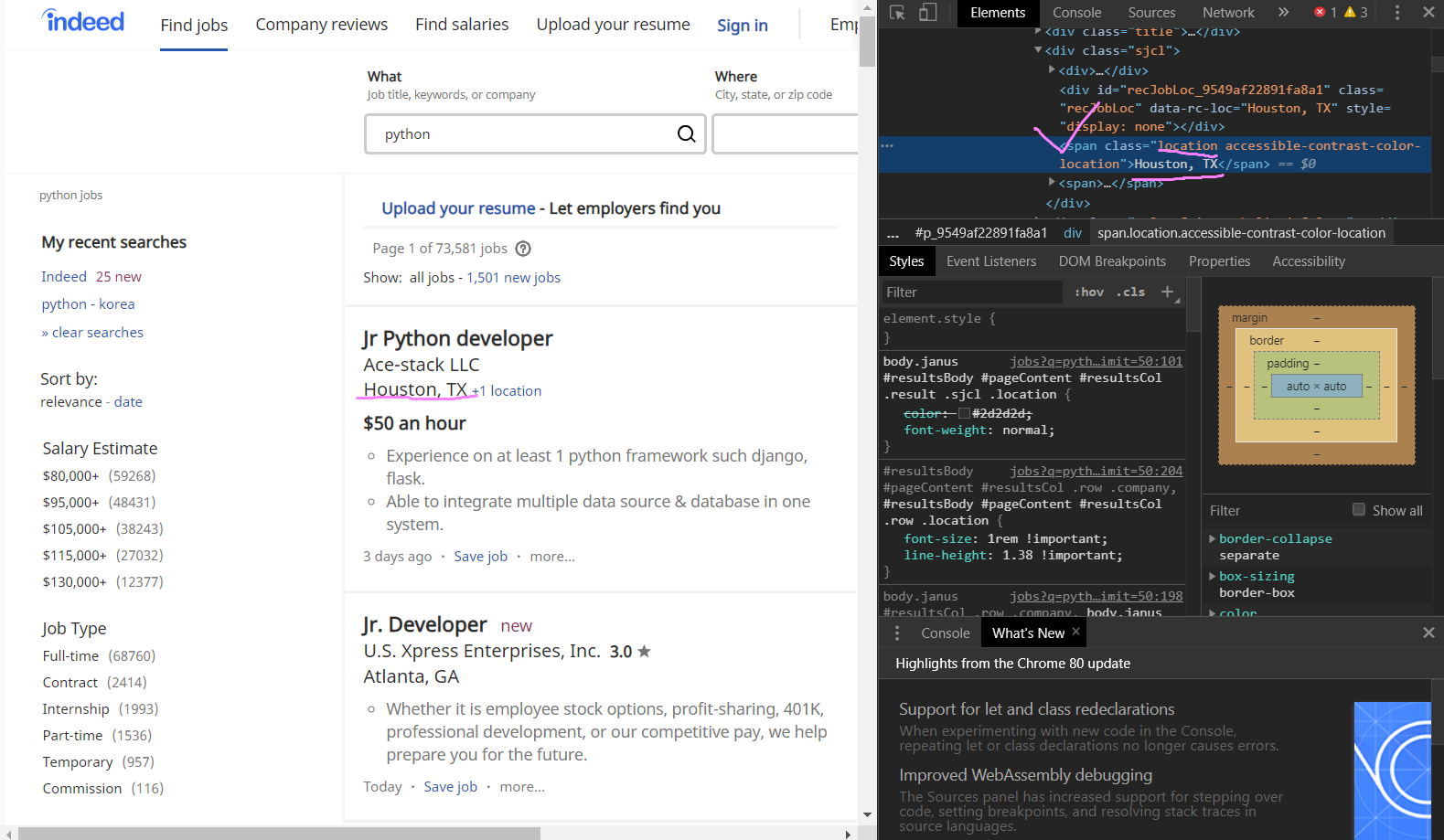
location은 URL링크도 없어서 더 쉬운 작업이 될 듯하다!!
span class="location"만 찾아서 string값으로 반환하면 될 듯!
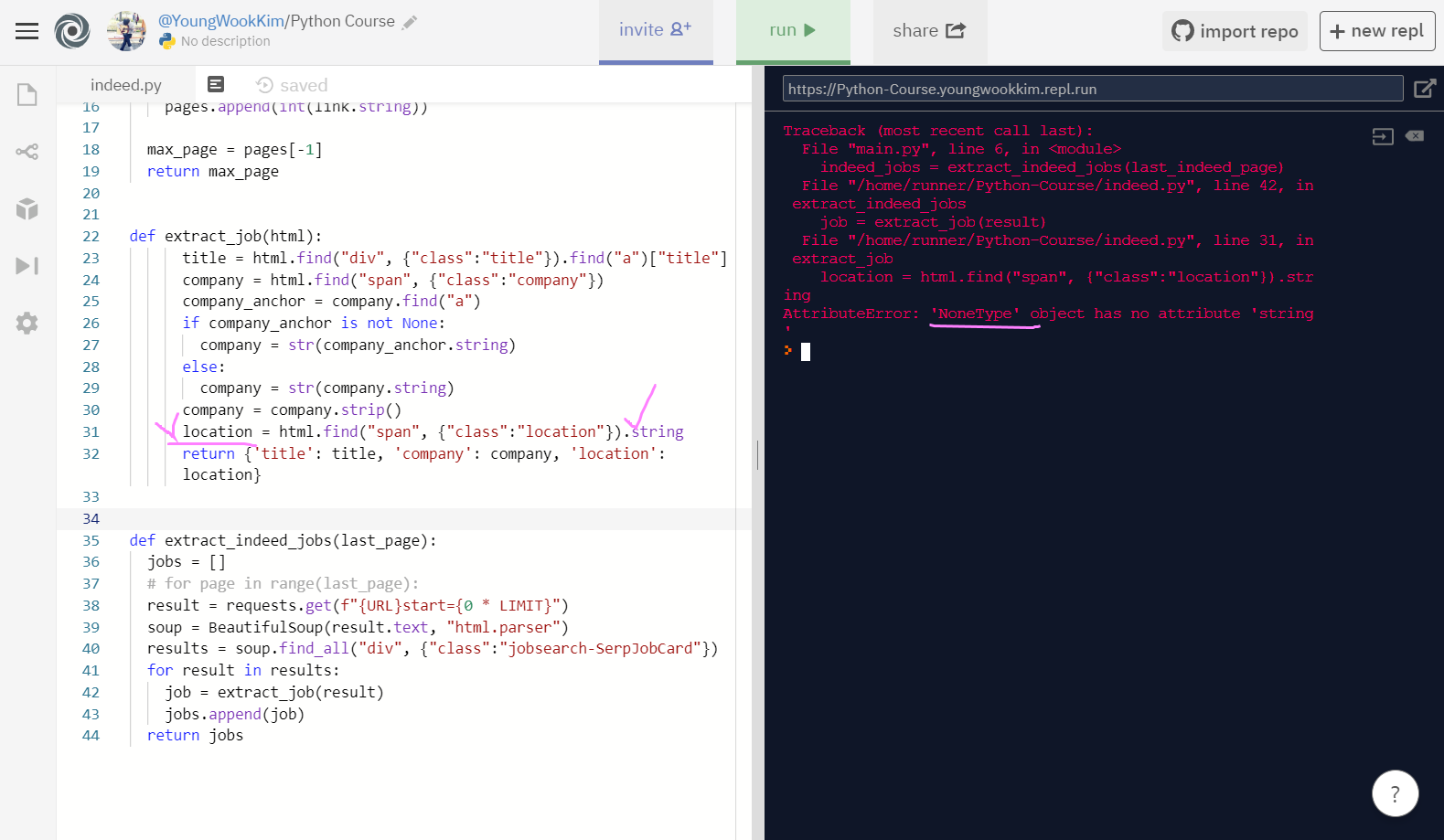
하지만 location에서 NoneType을 갖고있는 것이 있어서 string으로 반환하기 어렵다는 에러가 뜸... (여기부터 불안...)
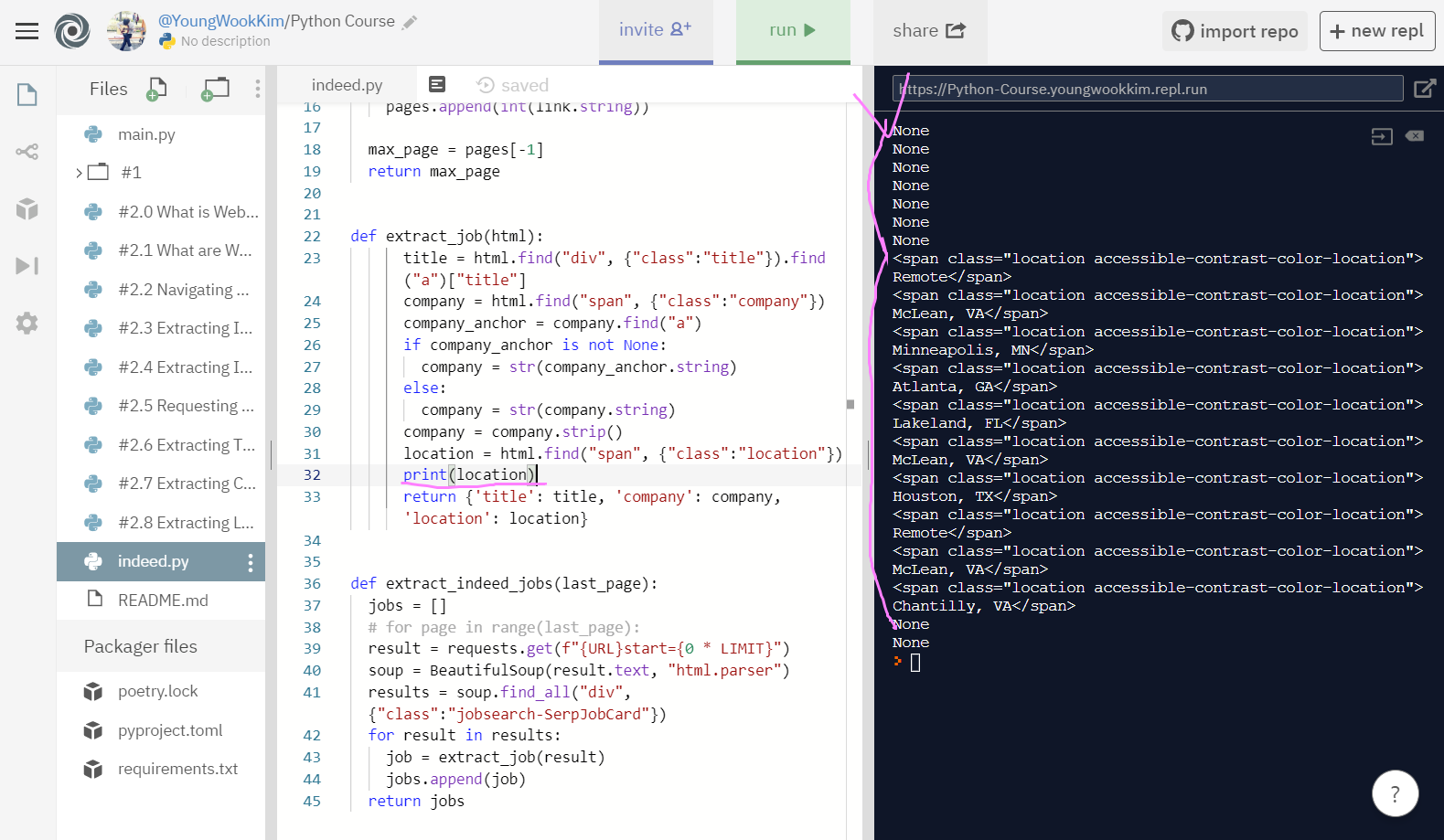
location을 string으로 반환해서 출력하지 않고, .string 반환없이 그냥 print(출력)하자 에러 내용대로 None 값이 나옴!
3. 홈페이지 div attribute(속성) 들여다보기
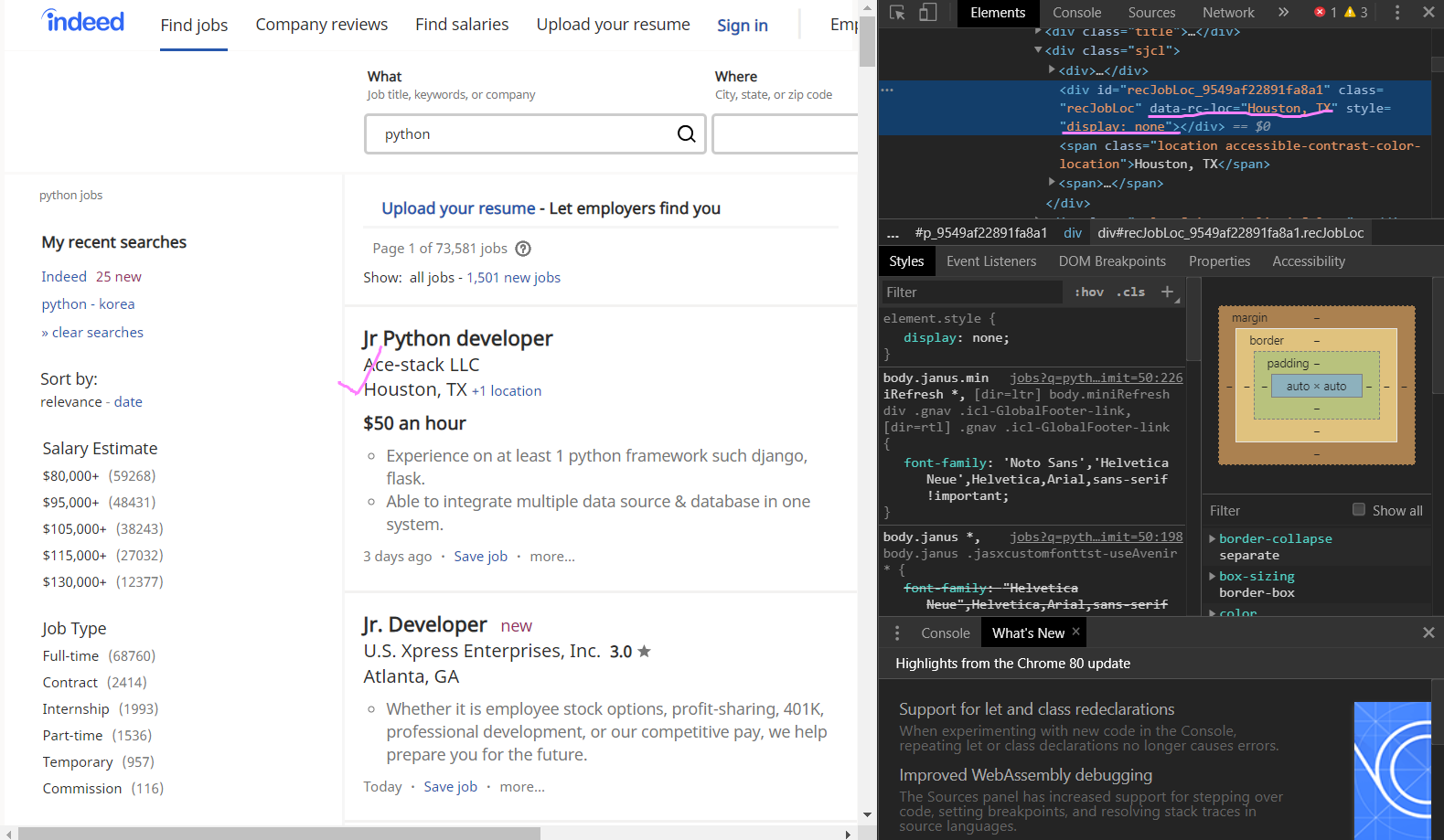
data-rc-loc="Houston, TX" 라고 회사명이 잘 나와있지만, style에는 "display: none" 이라는 값을 나타나게 되어있어서 오류가 남!
정리하자면 class, data-rc-loc, style은 div에 있는 attribute라고 생각하면 된다.
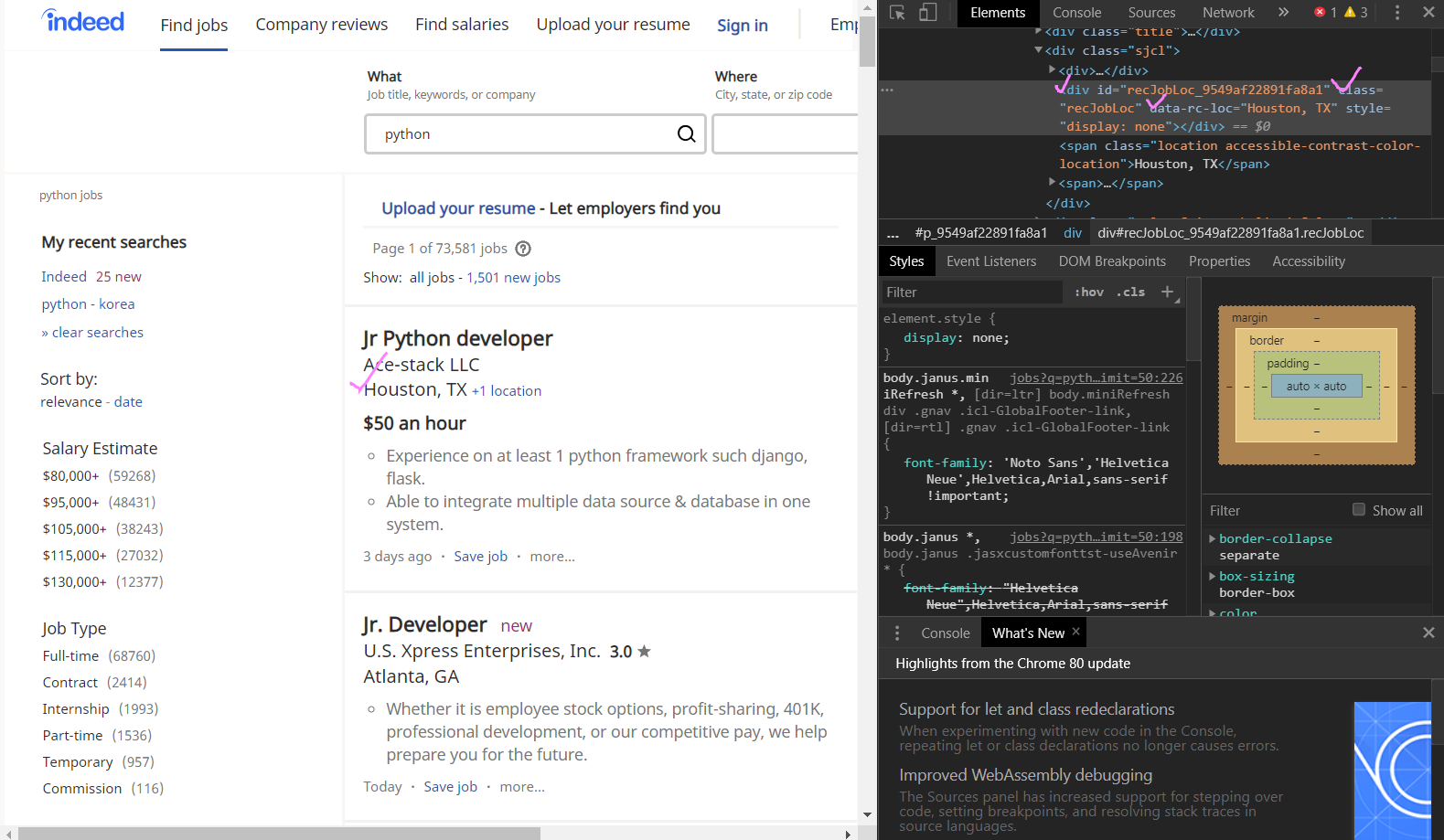
때문에 div, class="recJobLoc", 그 뒤 data-rc-loc만 입력해서 추출해보기!
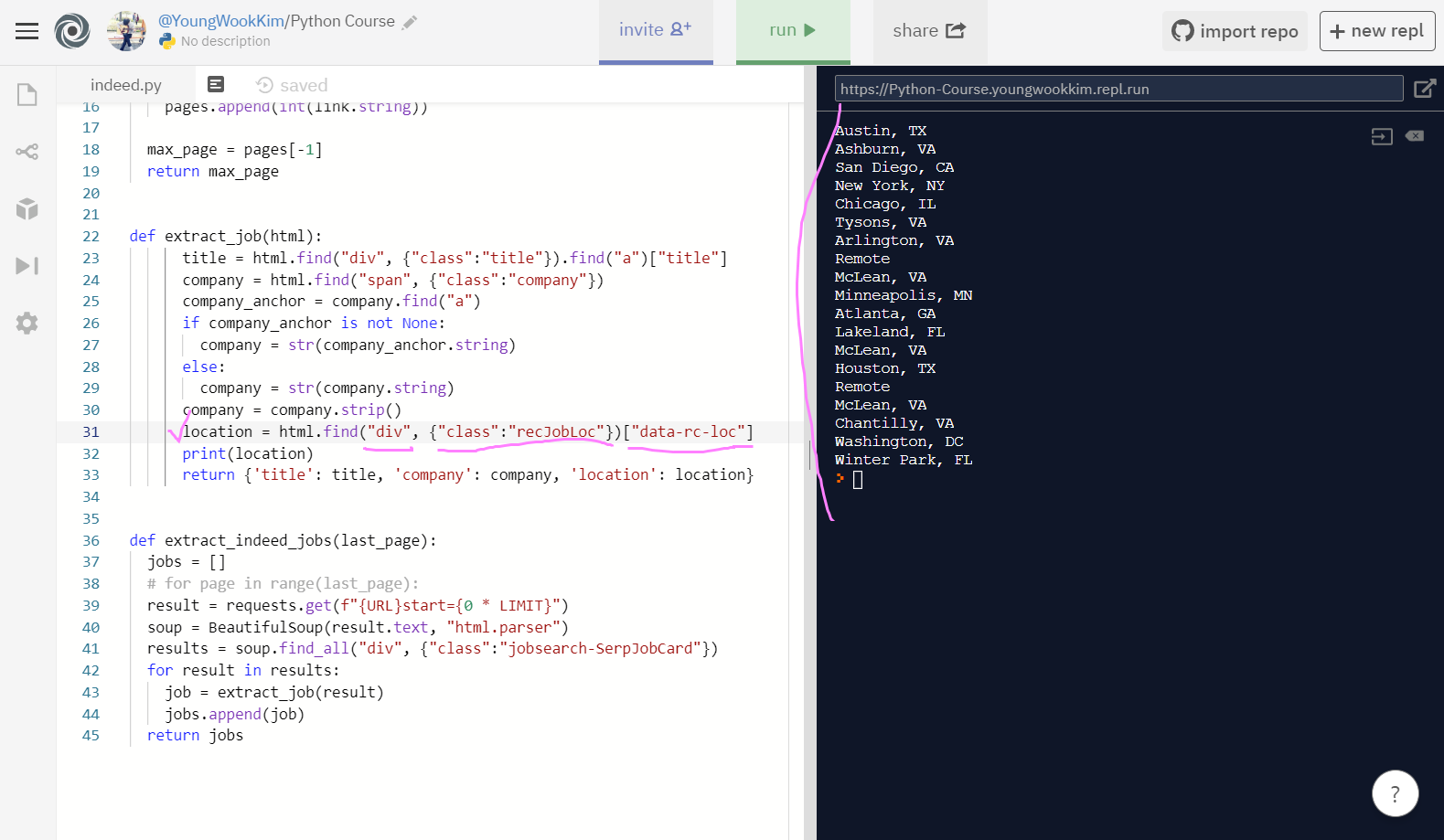
find("div", {"class":"recJobLoc"})["data-rc-loc"] None 값 없이 location 출력 대성공!
4. link가져오기
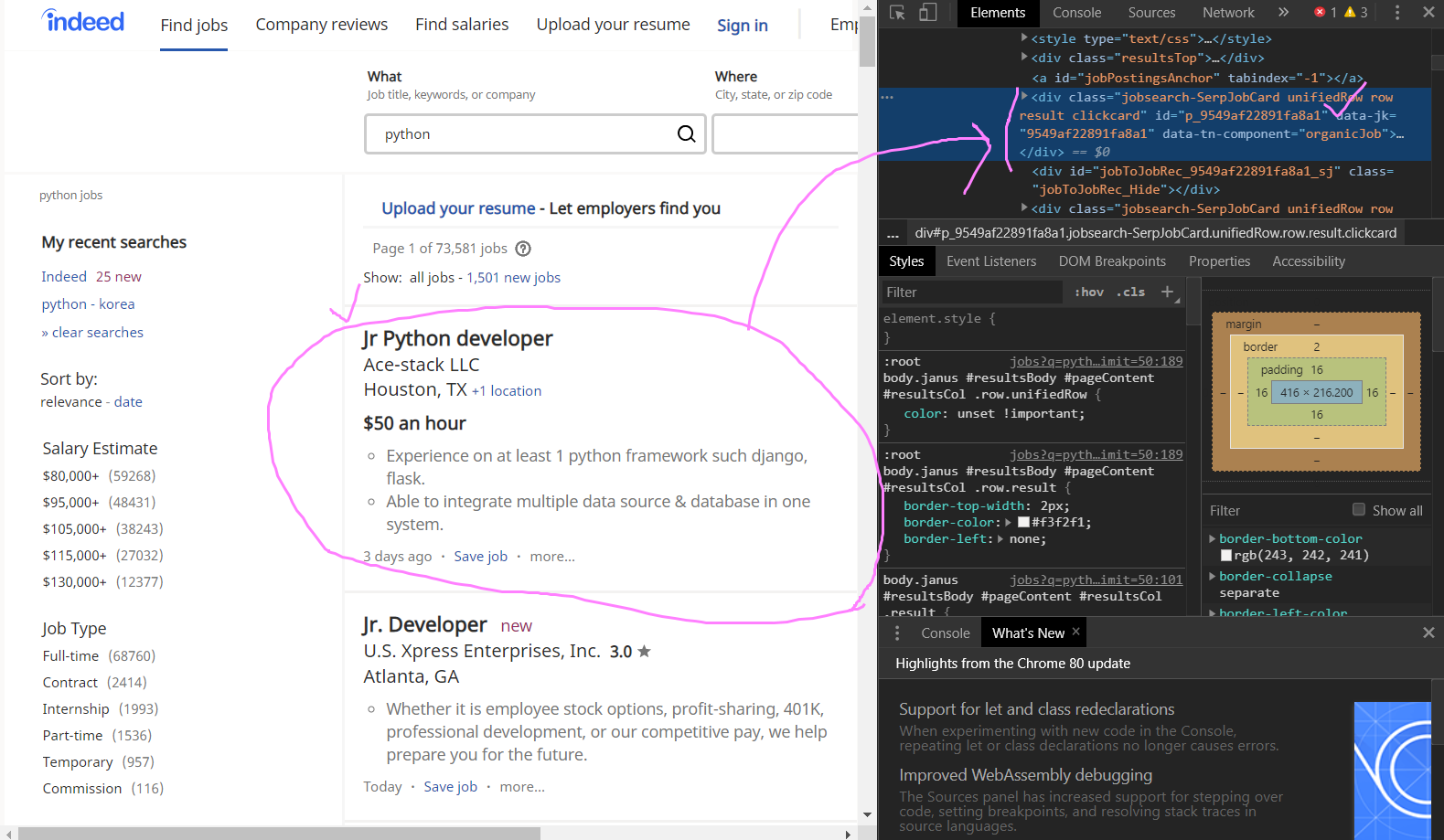
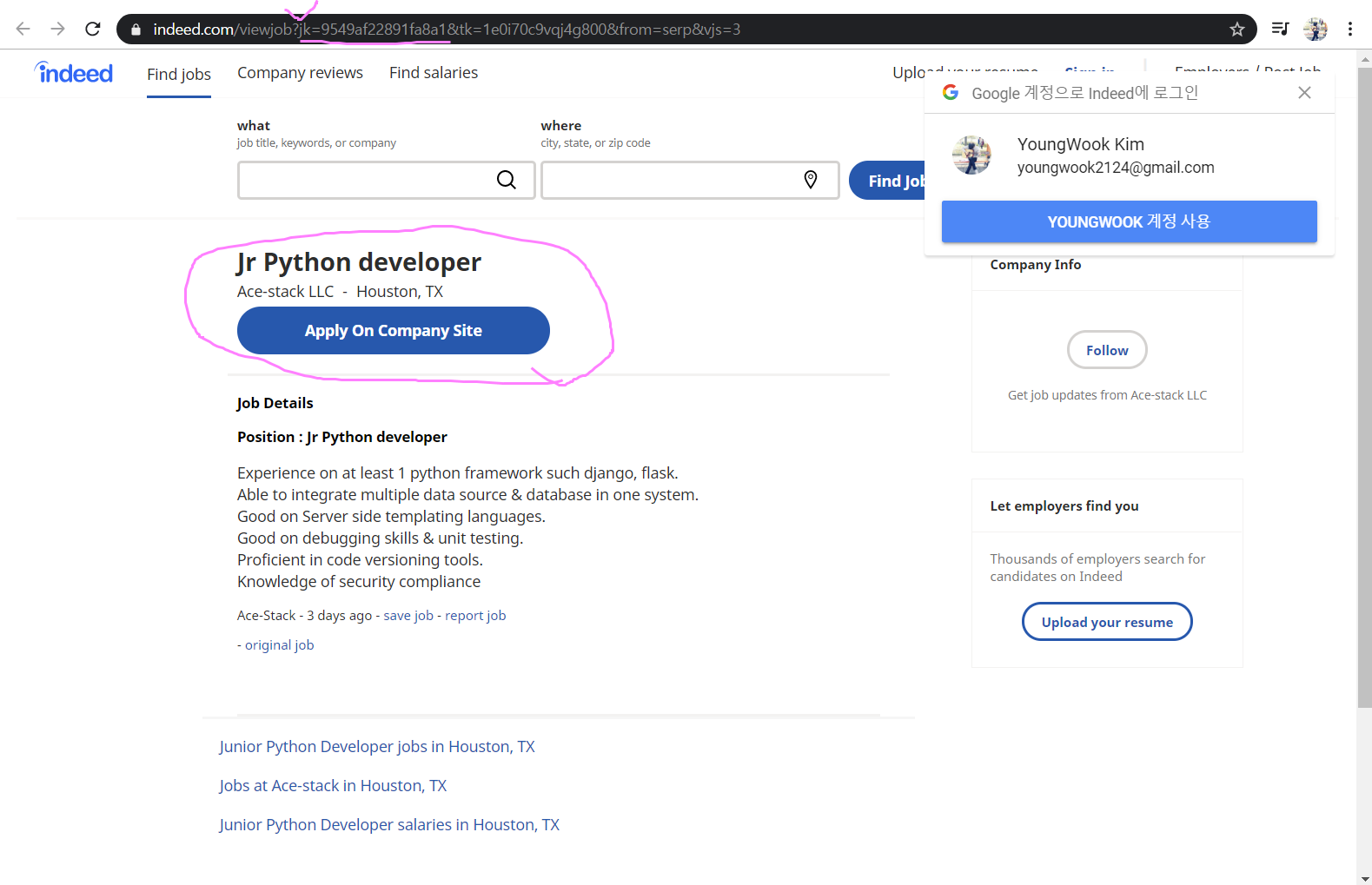
div 중 data-jk를 출력하면 되는데, 사진을 보고 구직사이트의 URL링크와 data-jk 값이 일치하는 것을 알 수 있다.
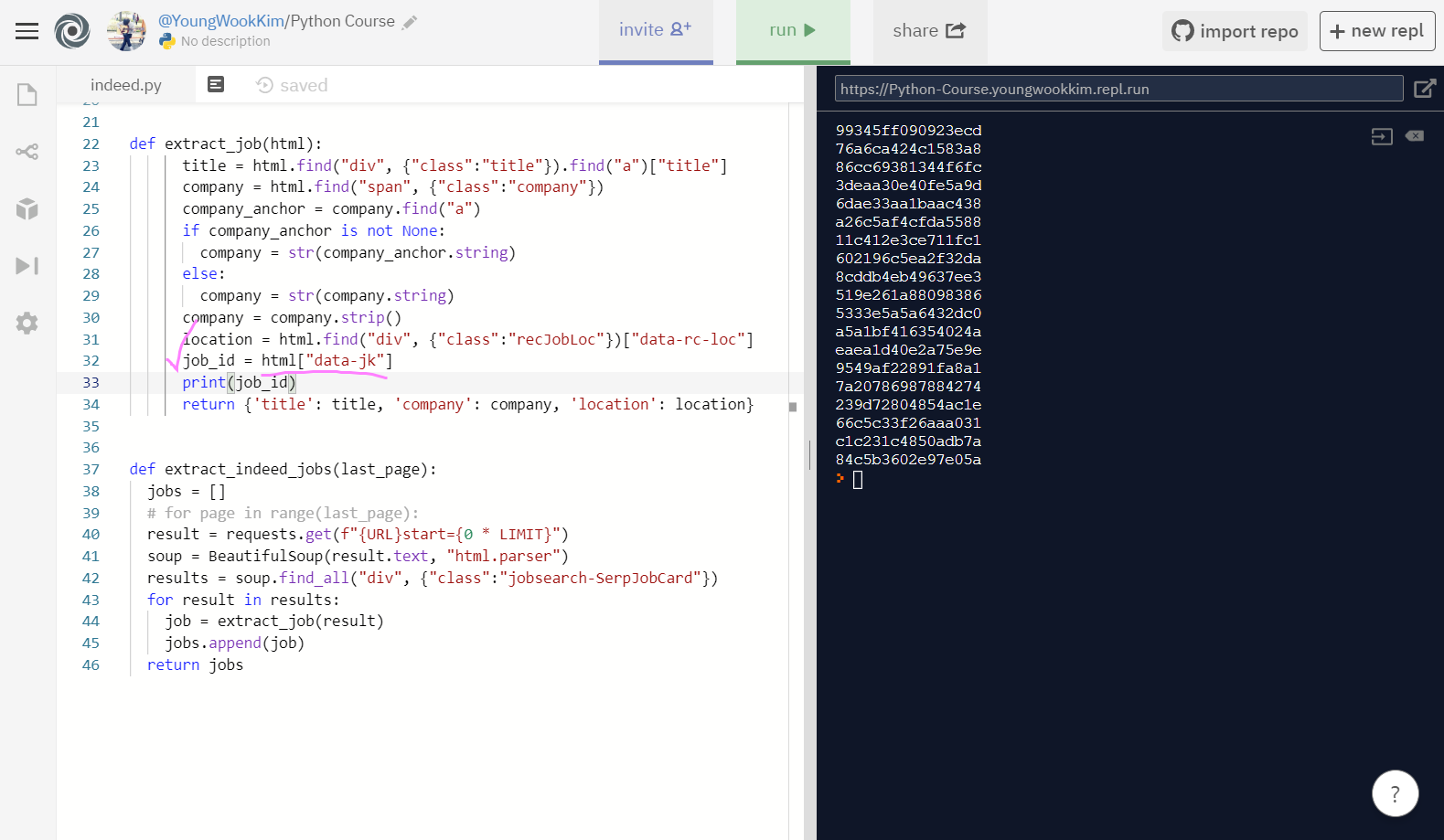
job_id = html["data-jk"] 출력 성공!
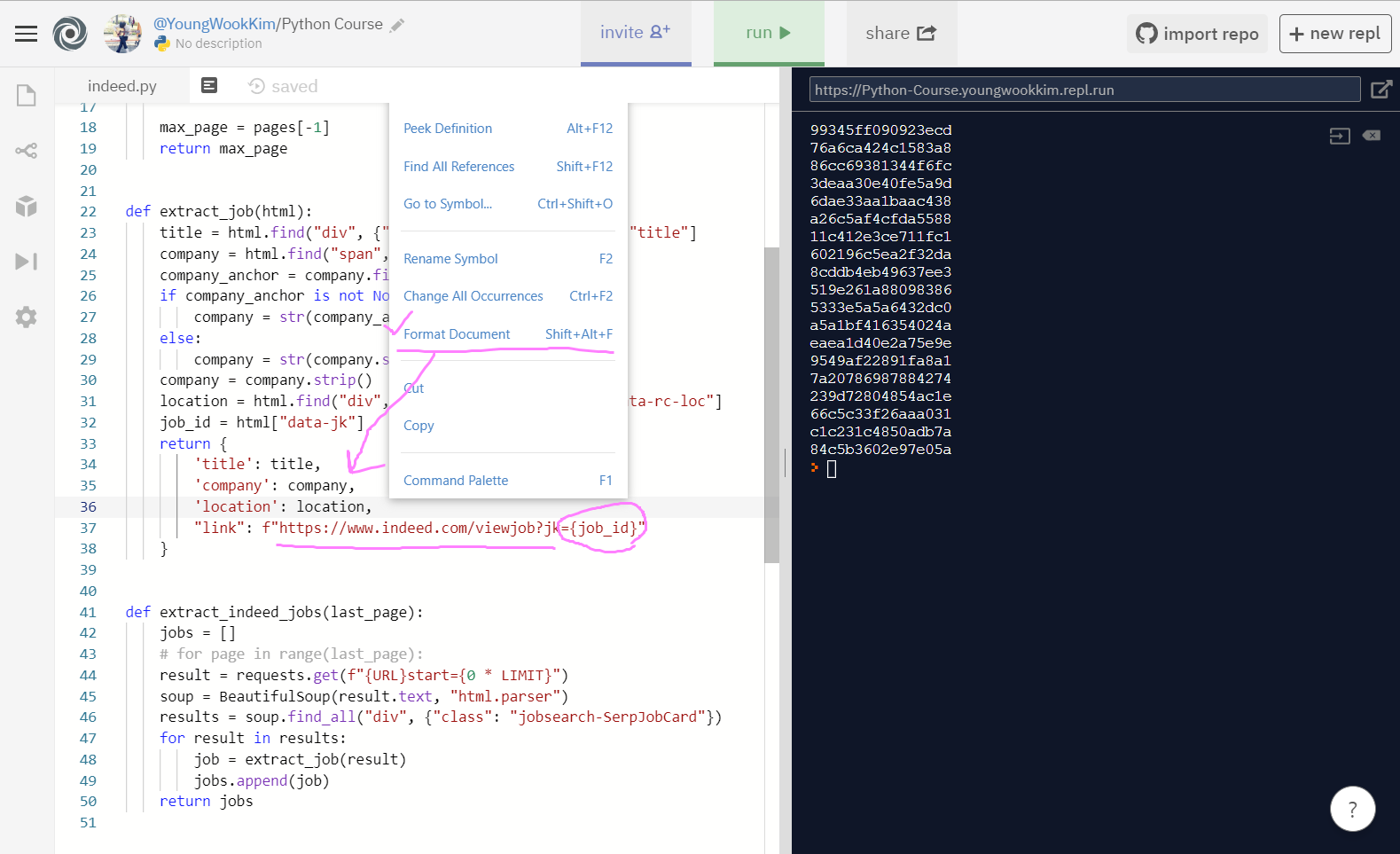
사이트 URL링크에 나온 것처럼 jk="data-jk의 값"을 {job_id} argument(인자)로 정해주고, Format Document를 통해 코드 포맷을 한번 정리해준다.
5. 최종 전체 페이지 출력해보기 (1~20page)
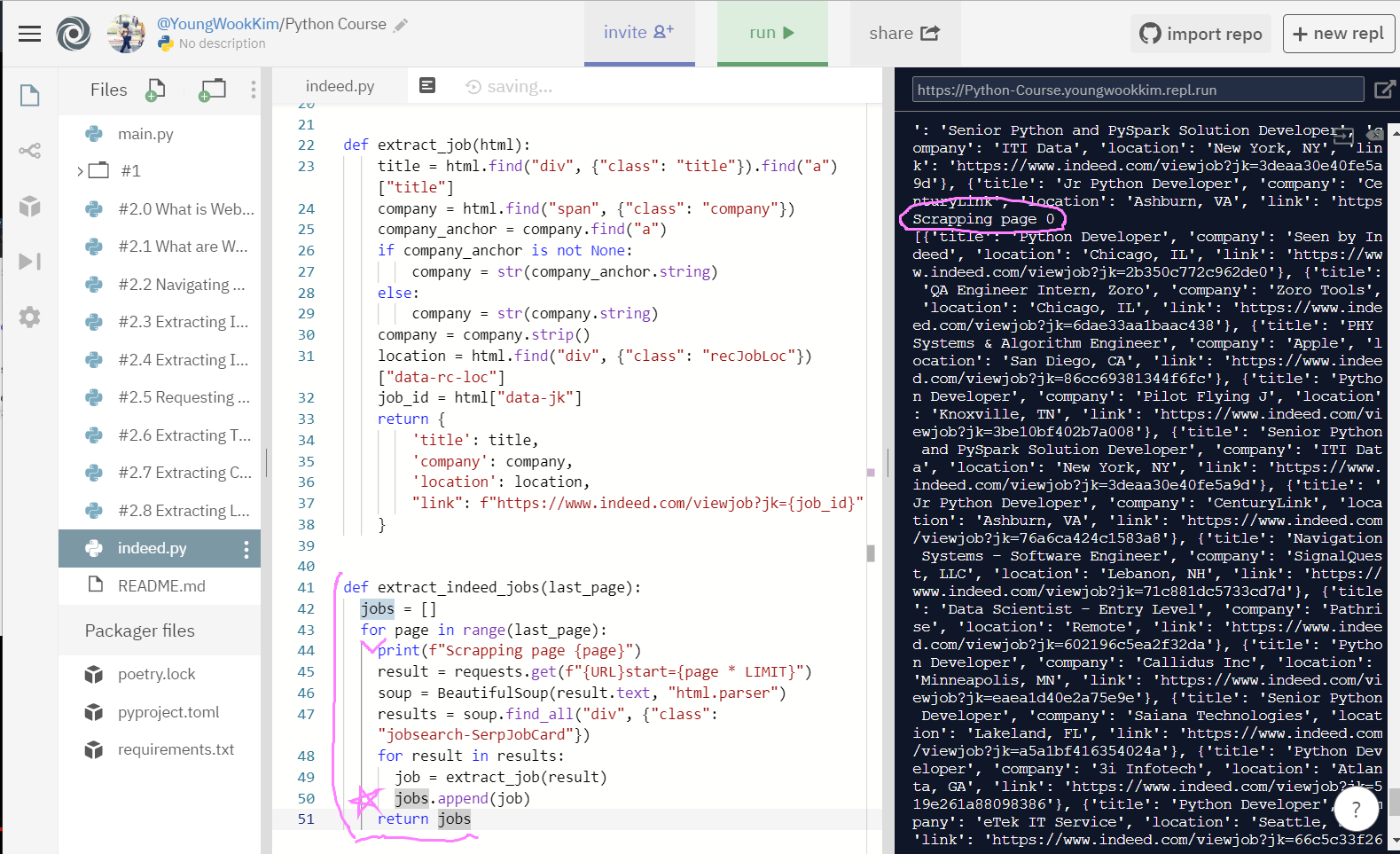
그러나 사진에 표시해둔 return jobs의 들여쓰기 문제로 0페이지만 출력이 됐다.
for page in range(last_page):와 같은 칸에 있어야함!!
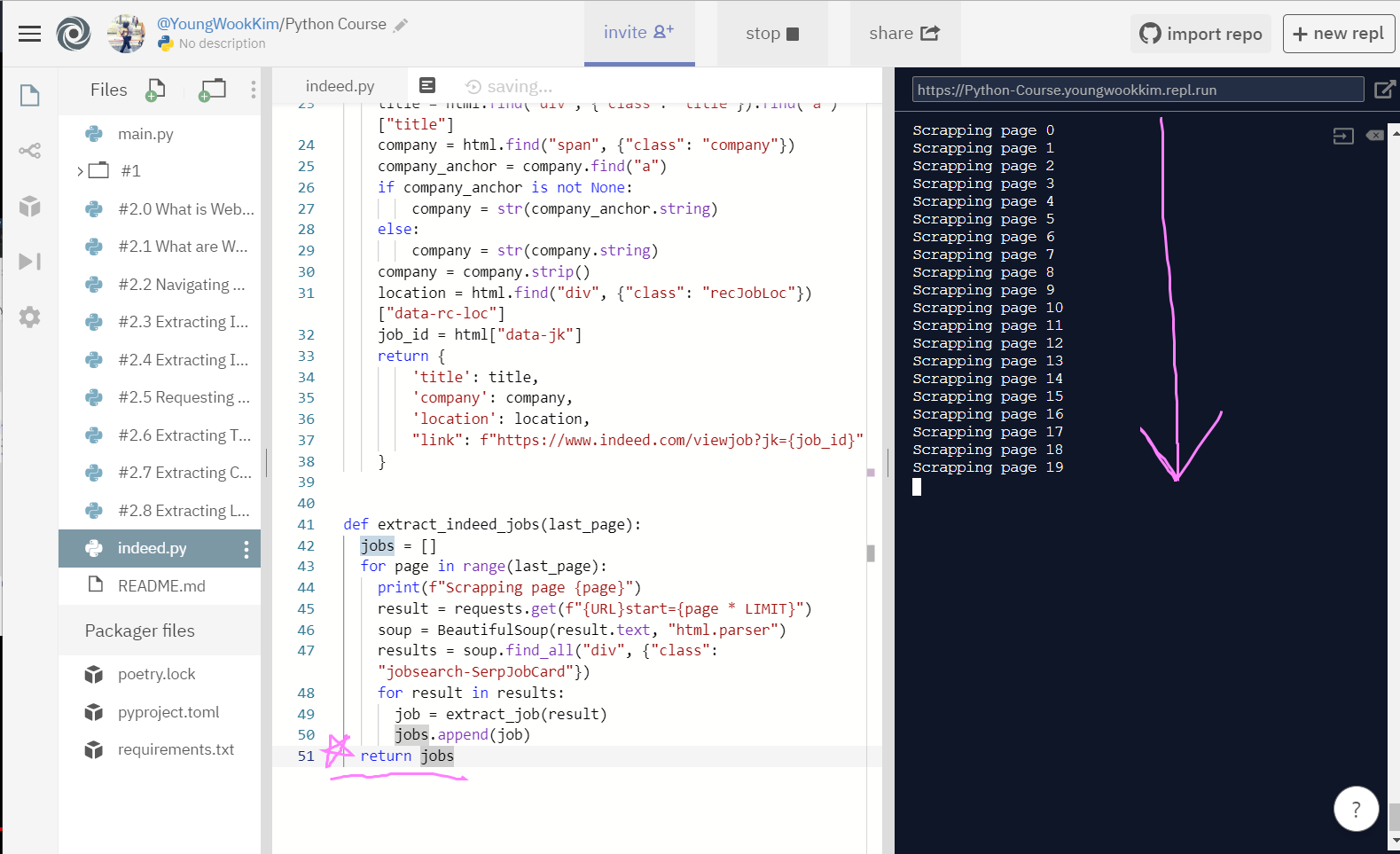
python 들여쓰기의 중요성을 깨달은 순간..!! 들여쓰기를 고쳐주자 20페이지 전체를 출력했다. (기계는 0부터 셈!)
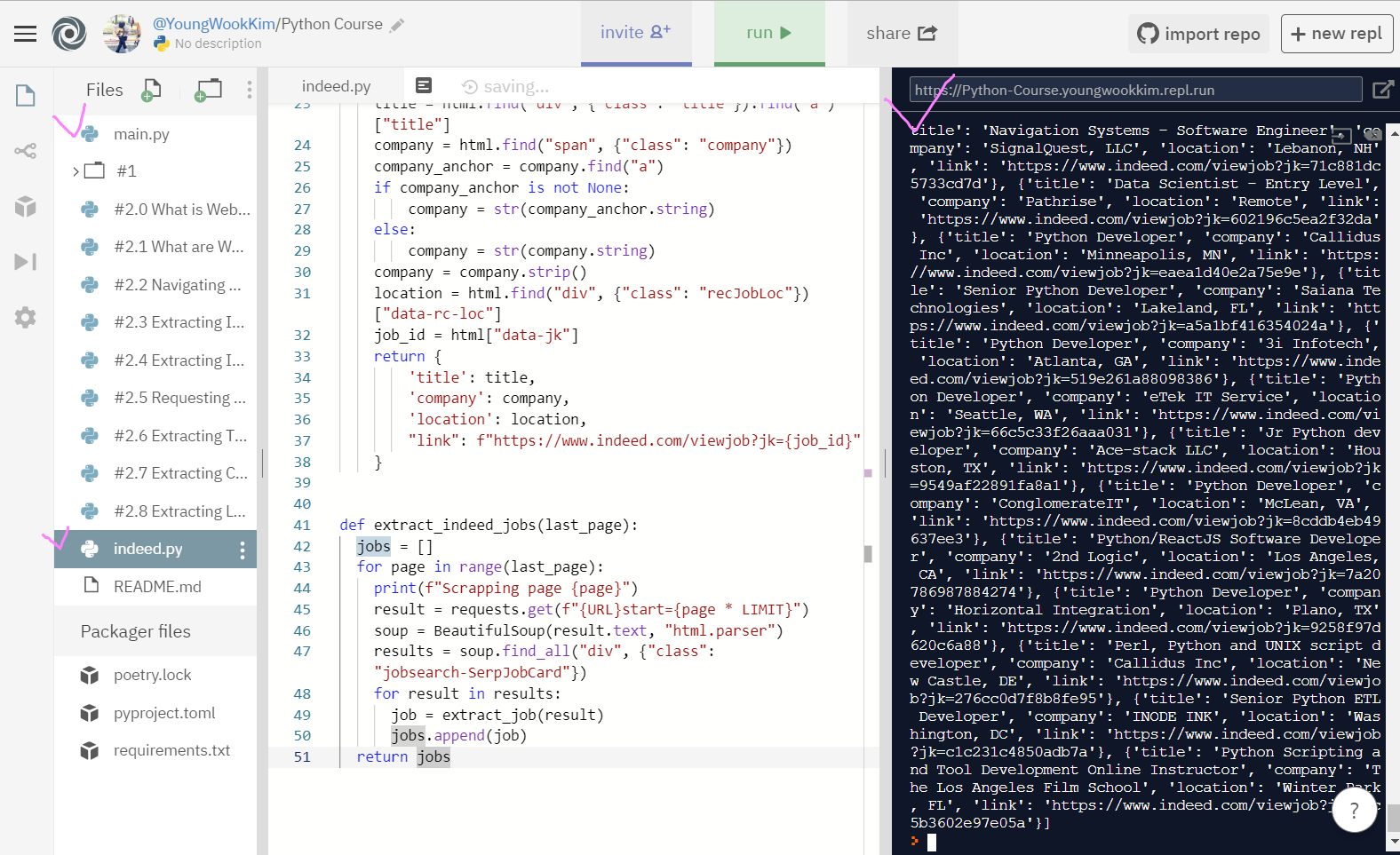
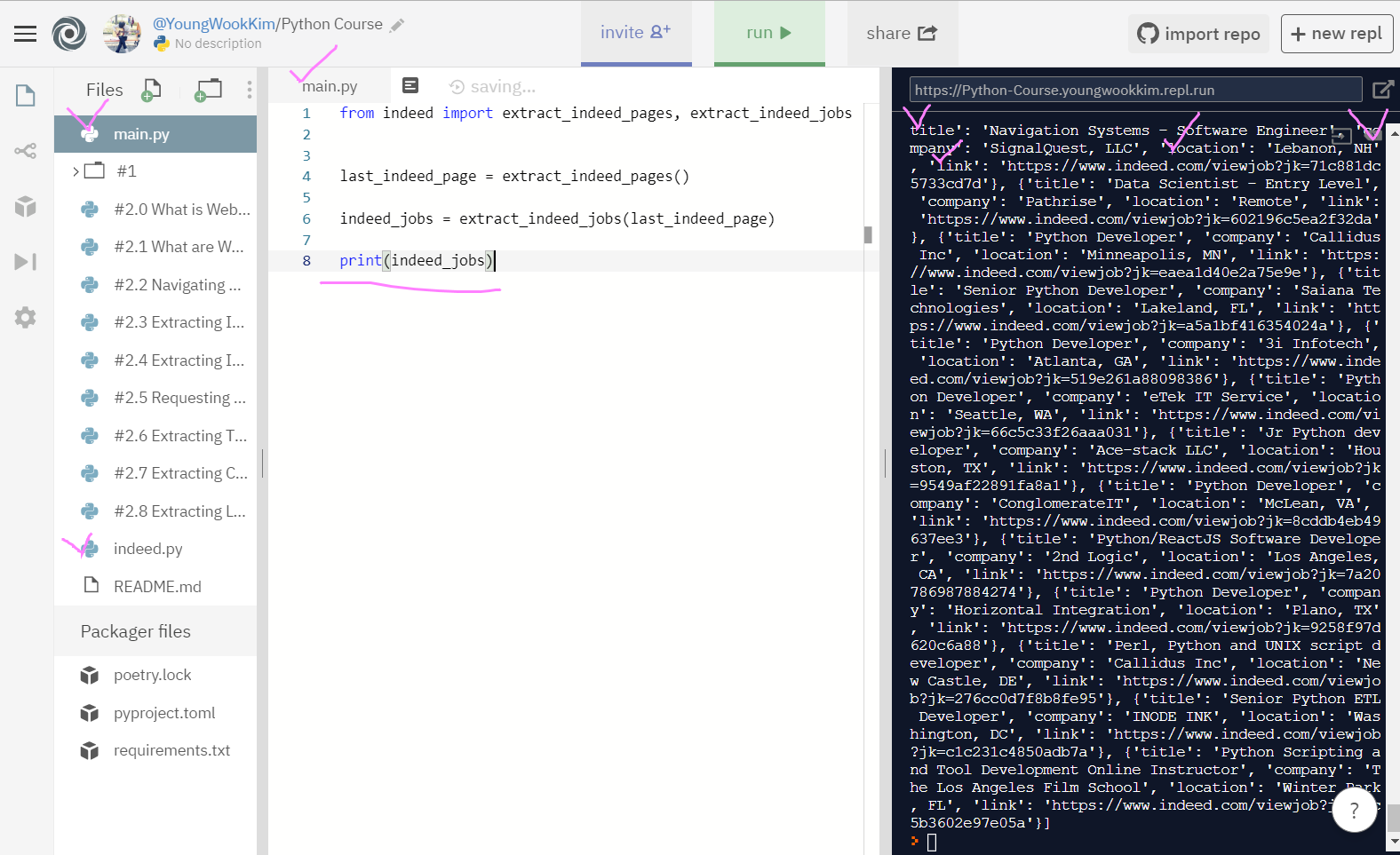
결과물!! 자세히 보면 [{'title', 'company', 'location', 'link'}] - [] link안에 {} dictionary로 정보가 정리되어있다.
indeed 홈페이지에서 1page부터 20page까지 pyhton에 관련된 구직정보를 다 뽑았다!
이렇게 뽑아낸 정보를 엑셀로 옮기는 작업은 stackoverflow Web Scraping까지 마치면 정리해보도록 하겠다. :)
※ 코로나바이러스감염증-19 조심하세요!!!!

'Python > Web Scraping' 카테고리의 다른 글
| [Python] #2.10 StackOverflow extract jobs (#코딩공부) (0) | 2020.02.22 |
|---|---|
| [Python] #2.9 StackOverflow Pages (#코딩공부) (0) | 2020.02.21 |
| [Python] #2.7 Extracting Companies (#코딩공부) (0) | 2020.02.20 |
| [Python] #2.6 Extracting Titles (#코딩공부) (0) | 2020.02.19 |
| [Python] #2.5 Requesting Each Page (#코딩공부) (0) | 2020.02.17 |




댓글