<복습>
https://wook-2124.tistory.com/35
[Python] #2.6 Extracting Titles (#코딩공부)
https://youtu.be/3vfIMmZeNNY <복습> https://wook-2124.tistory.com/31 [Python] #2.4 Extracting Indeed Pages part Two (#코딩공부) https://youtu.be/YKY9SFm1cfw <복습> https://wook-2124.tistory.com/29 [..
wook-2124.tistory.com
<준비물>
The world's leading online coding platform
Powerful and simple online compiler, IDE, interpreter, and REPL. Code, compile, and run code in 50+ programming languages: Clojure, Haskell, Kotlin (beta), QBasic, Forth, LOLCODE, BrainF, Emoticon, Bloop, Unlambda, JavaScript, CoffeeScript, Scheme, APL, Lu
repl.it
https://github.com/psf/requests
psf/requests
A simple, yet elegant HTTP library. Contribute to psf/requests development by creating an account on GitHub.
github.com
https://www.crummy.com/software/BeautifulSoup/
Beautiful Soup: We called him Tortoise because he taught us.
www.crummy.com
<코드기록>
# anchor안에 URL이 있는 회사와 없는 회사를 if else로 나눔!
# 만약 anchor 안에 URL이 있다면 None 값이 나오지 않음.
# anchor안에 URL이 있는 회사와 없는 회사를 if else로 나눔!
# 만약 anchor 안에 URL이 있다면 None 값이 나오지 않음.
# None 값이 나온다면 anchor 안에 URL이 없기에 else로 가서 출력이 됨.
# 그러나 이렇게 하면 빈칸이 너무 많이 나옴.
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class":"pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_page):
jobs = []
# for page in range(last_page):
result = requests.get(f"{URL}start={0 * LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class":"jobsearch-SerpJobCard"})
for result in results:
title = result.find("div", {"class":"title"}).find("a")["title"]
company = result.find("span", {"class":"company"})
company_anchor = company.find("a")
if company_anchor is not None:
print(str(company_anchor.string))
else:
print(str(company.string))
return jobs
# if, else구문을 끝내고 string.strip() << 이용해서 빈칸을 없앰!
def extract_indeed_jobs(last_page):
jobs = []
# for page in range(last_page):
result = requests.get(f"{URL}start={0 * LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class":"jobsearch-SerpJobCard"})
for result in results:
title = result.find("div", {"class":"title"}).find("a")["title"]
company = result.find("span", {"class":"company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
print(company)
return jobs
# 최종코드, title과 company 출력하기
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class":"pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_page):
jobs = []
# for page in range(last_page):
result = requests.get(f"{URL}start={0 * LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class":"jobsearch-SerpJobCard"})
for result in results:
title = result.find("div", {"class":"title"}).find("a")["title"]
company = result.find("span", {"class":"company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
print(title, company)
return jobs1. Company 추출하기

span class="company"를 가져와보자!
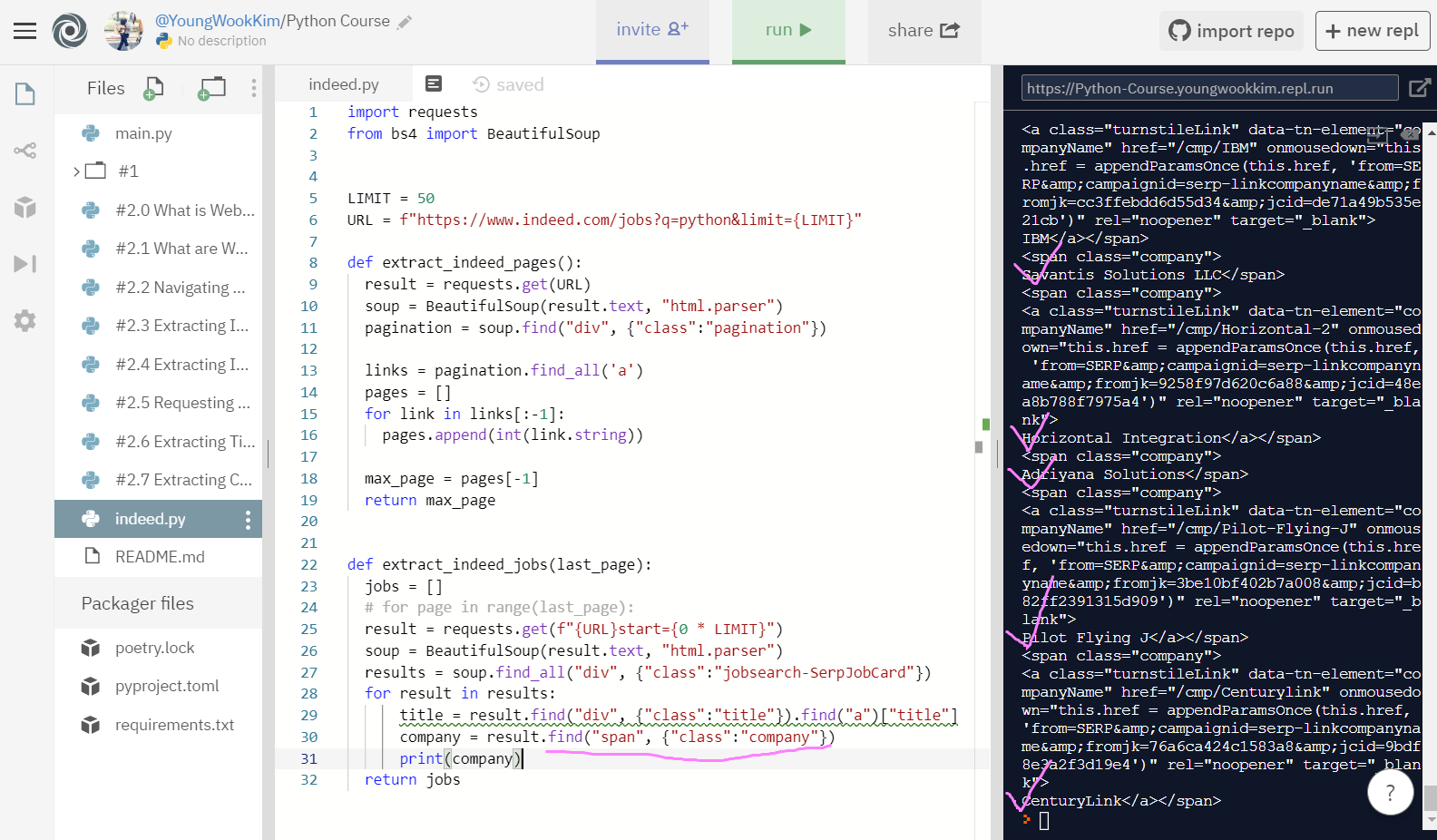
복잡하지만 일단 company = result.find("span", {"class":"company"}) 를 입력해서 나와있는 내용 전체를 다 가져왔다.
result 값이 requests.get으로 1page부터 20page의 결과를 가져온 것이라 깔끔하지 않게 company가 아닌 내용도 너무 많이 담겨있으므로 수정이 필요하다.
2. span class:"company"안에 있는 a(anchor)로 추출하기
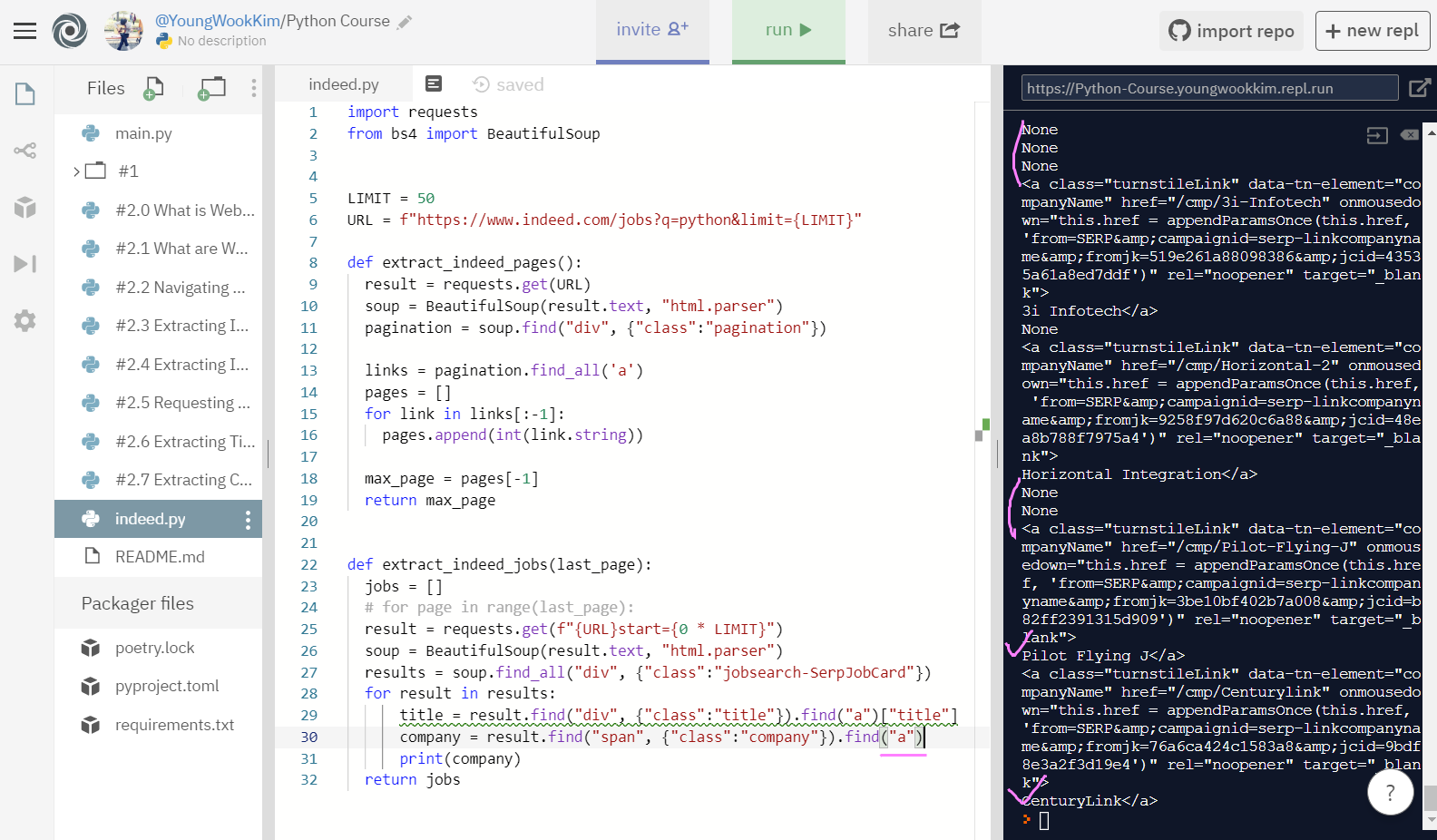
find("a")로 anchor를 .find 하자 company에 대한 내용으로만 제대로 추출됐긴했지만, 그럼에도 회사가 사이트 내에 입력되어있지 않아 None이 나오는 경우가 있다.
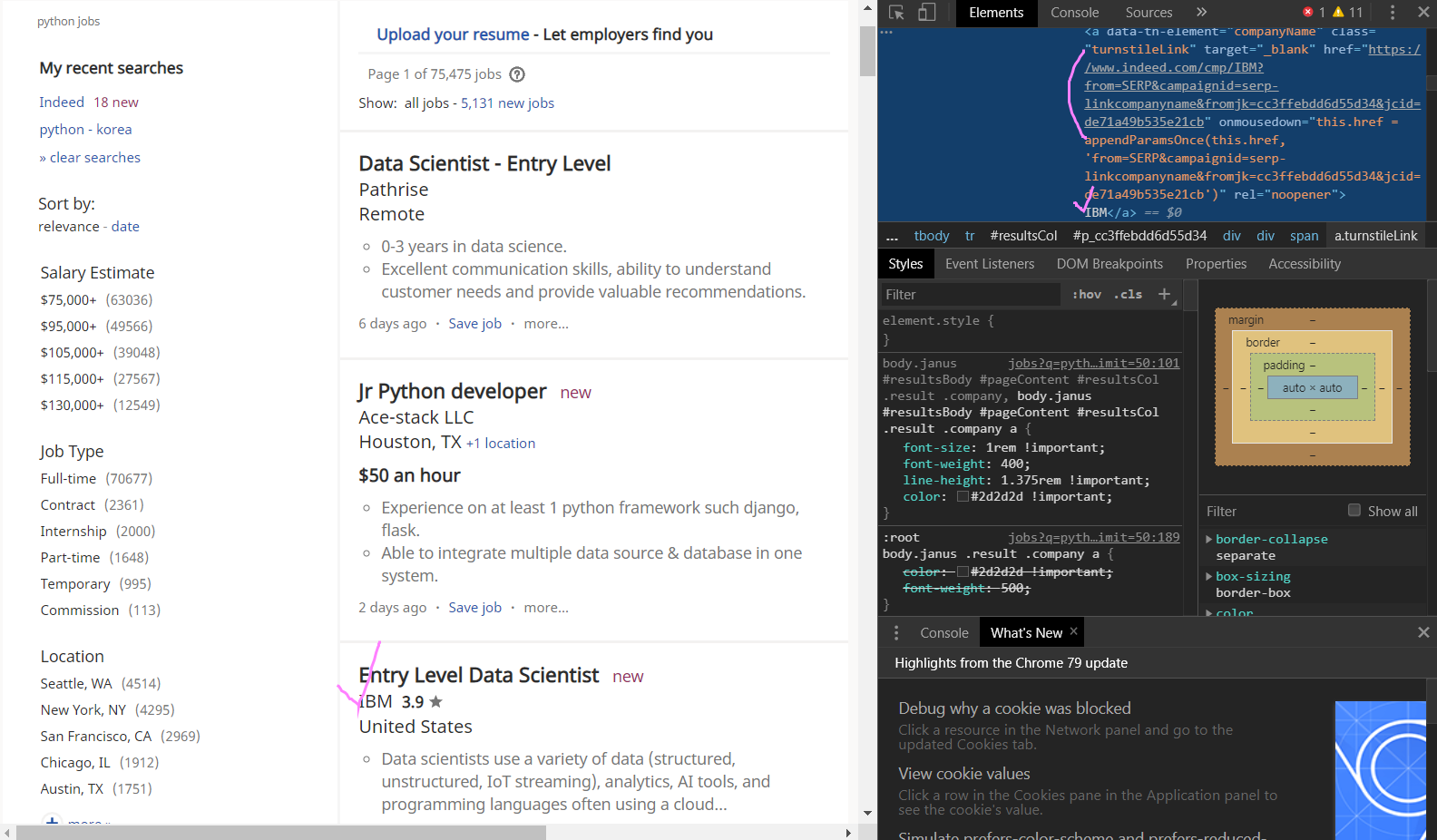
이렇게 span class:"company" 안의 a(anchor) data-tn-element에 보이는 것처럼 href="URL링크"와 함께 IBM 회사가 나오는 곳과
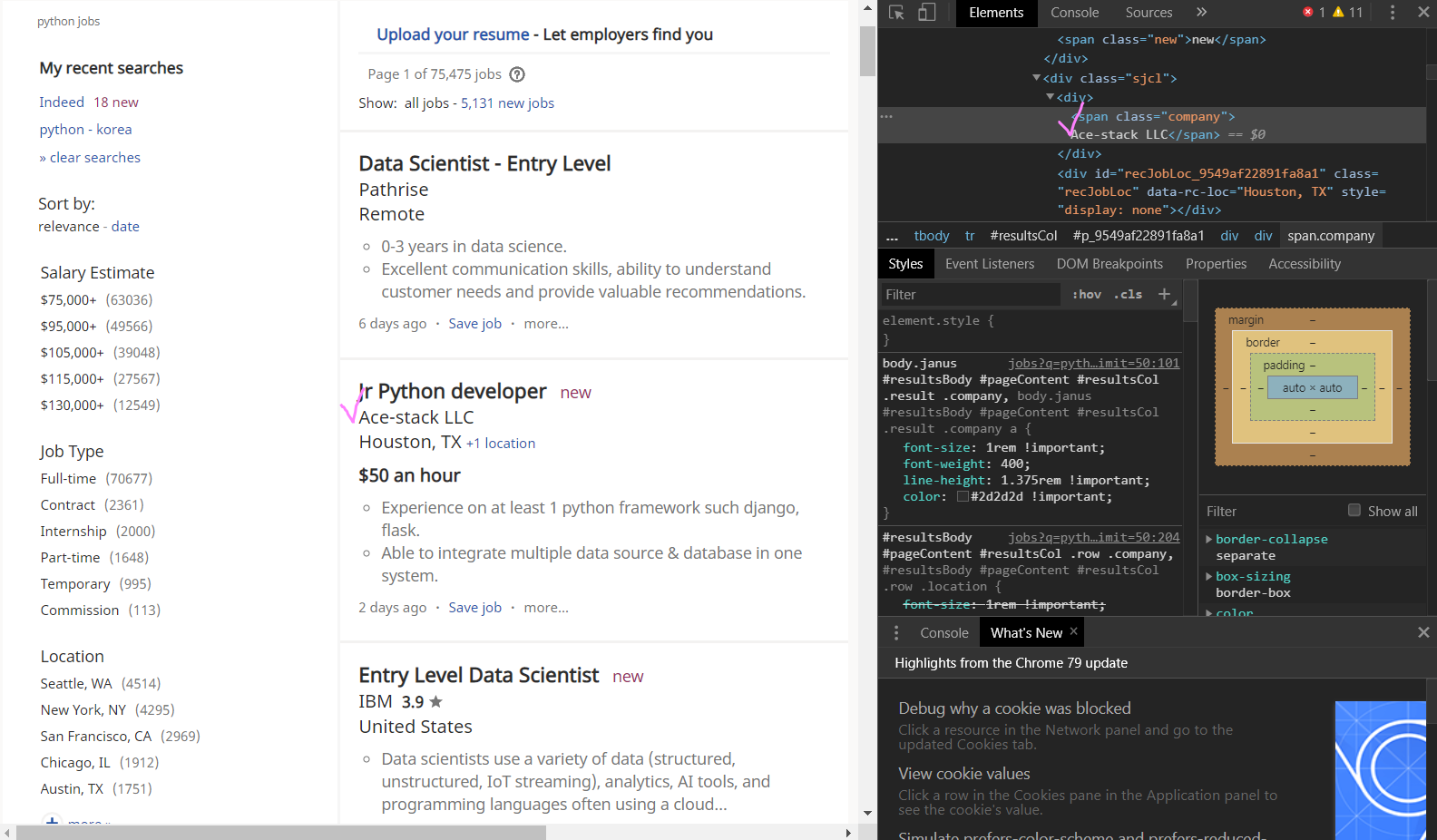
span class="company" 안에 URL링크 없이 회사의 이름 Ace-stack LLC만 나오는 경우 때문에 None값이 나오는 것!
3. if, else문 사용하기 - if company.find('a') is not None:=

if(만약) span class="company" a(anchor)에 URL링크가 있다면 None이 없는 회사(is not None)이기 때문에 find("a")를 해서 출력하고,
else(반대로) URL링크가 없이 span class="company"만 있어서 None으로 나오는 회사는 그대로 find("a")하지 않고 stirng(문자열)으로만 출력! 성공!!
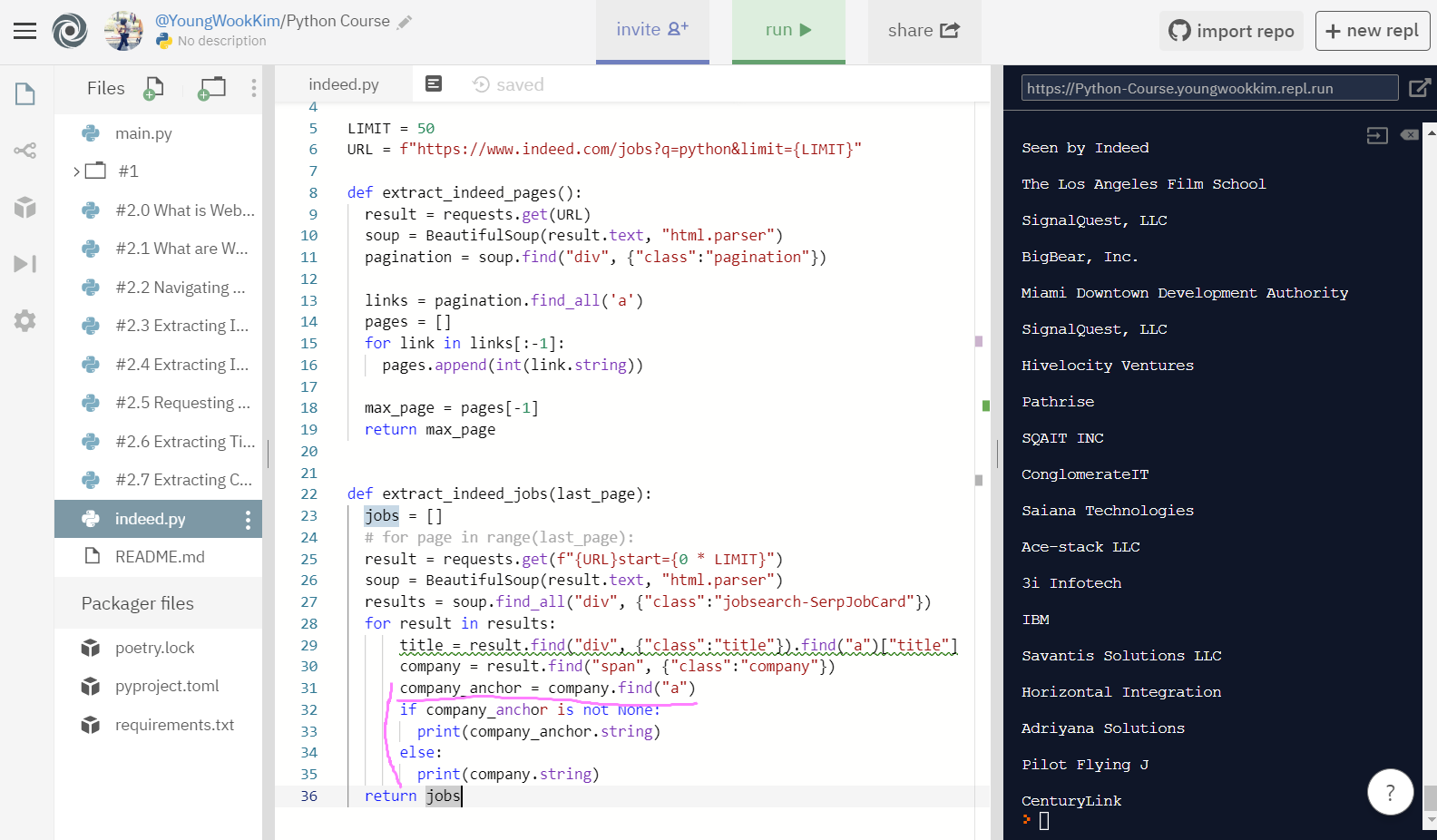
company_anchor = company.find('a')로 코드를 살짝 수정해주자. 예쁜 코드~ :) ㅋㅋㅋ
4. string.strip - 빈칸지우기 기능 사용하기

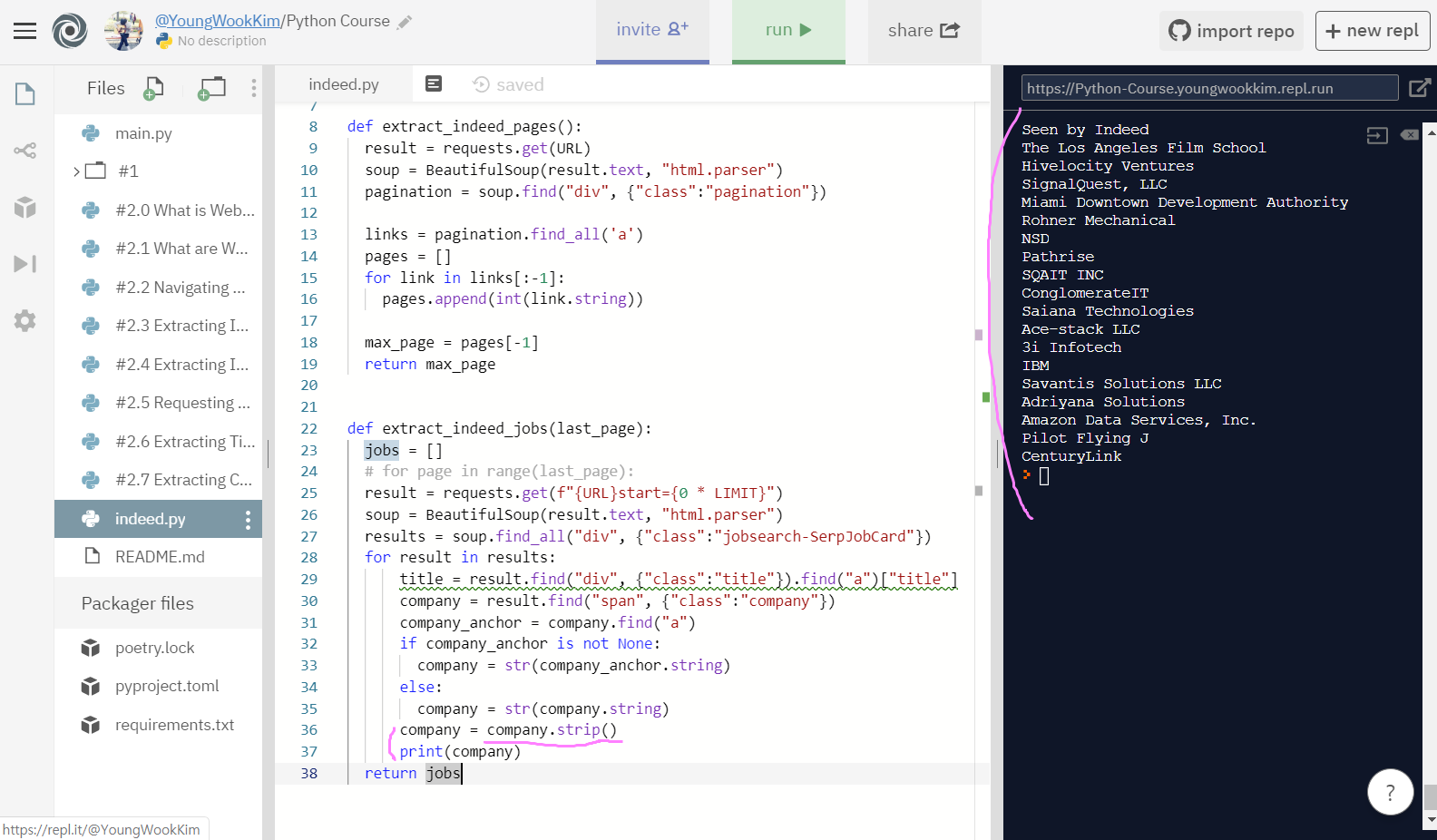
company.strip()에서 만약 () 괄호 안에 'F'를 넣으면 string으로 출력되는 F가 들어가있는 문장에서 F문자를 다 없애준다.
() 괄호 안에 아무것도 입력하지 않으면 빈칸을 지워준다!!
5. 최종코드, title과 company 출력하기
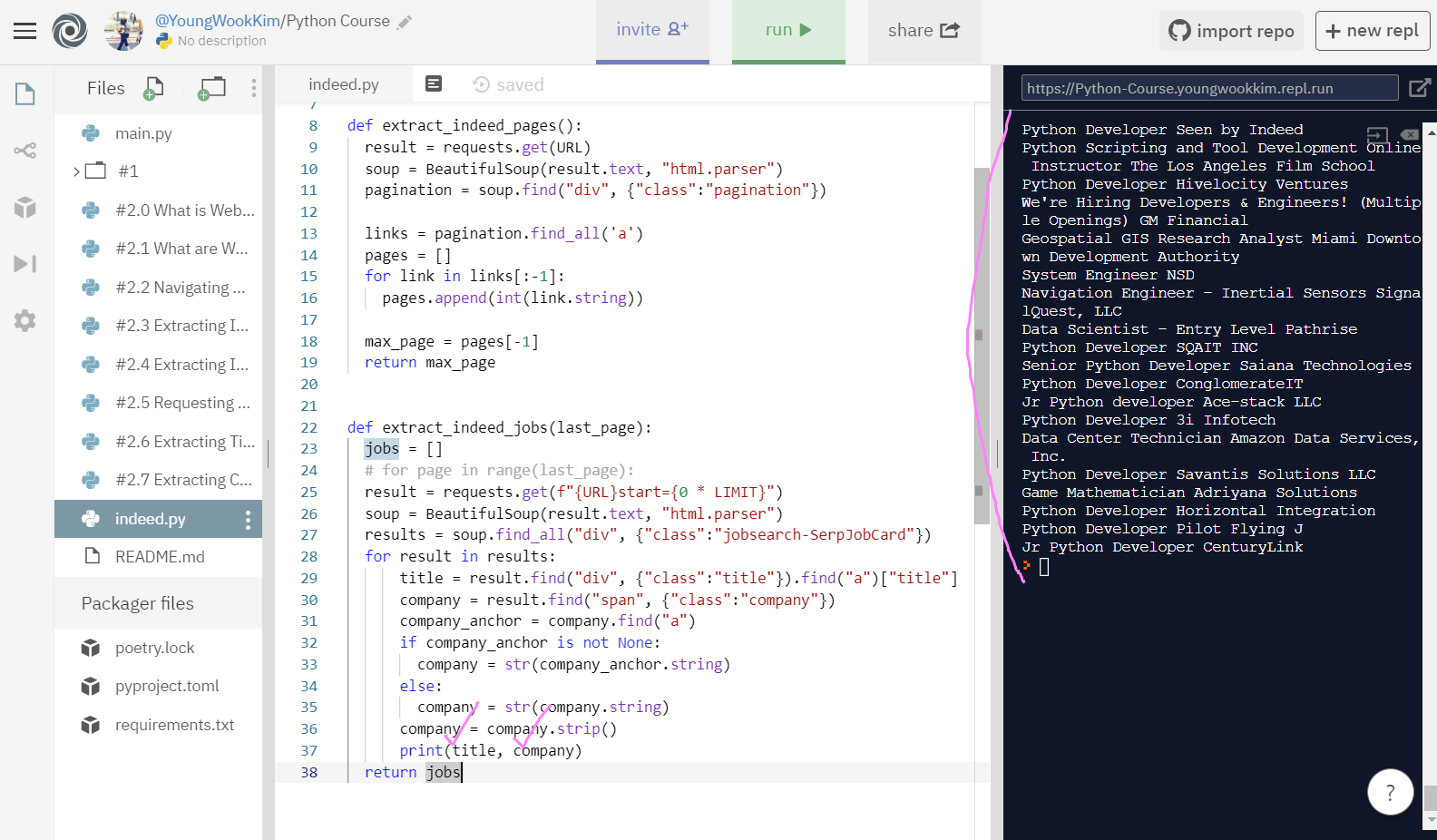
# 최종코드, title과 company 출력하기
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class":"pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_page):
jobs = []
# for page in range(last_page):
result = requests.get(f"{URL}start={0 * LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class":"jobsearch-SerpJobCard"})
for result in results:
title = result.find("div", {"class":"title"}).find("a")["title"]
company = result.find("span", {"class":"company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
print(title, company)
return jobstitle과 company 같이 추출해오기, 성공!!!
다음 시간에 indeed 홈페이지는 마무리 지어보도록 하겠다. :)
※ 코로나바이러스감염증-19 조심하세요!!!!

'Python > Web Scraping' 카테고리의 다른 글
| [Python] #2.9 StackOverflow Pages (#코딩공부) (0) | 2020.02.21 |
|---|---|
| [Python] #2.8 Extracting Locations and Finishing up (#코딩공부) (0) | 2020.02.21 |
| [Python] #2.6 Extracting Titles (#코딩공부) (0) | 2020.02.19 |
| [Python] #2.5 Requesting Each Page (#코딩공부) (0) | 2020.02.17 |
| [Python] #2.4 Extracting Indeed Pages part Two (#코딩공부) (0) | 2020.02.16 |




댓글