<복습>
https://wook-2124.tistory.com/37
[Python] #2.8 Extracting Locations and Finishing up (#코딩공부)
https://youtu.be/Qfchx372rhU <복습> https://wook-2124.tistory.com/36 [Python] #2.7 Extracting Companies (#코딩공부) https://youtu.be/tIHRPj8vbxE <복습> https://wook-2124.tistory.com/35 [Python] #2.6..
wook-2124.tistory.com
<준비물>
The world's leading online coding platform
Powerful and simple online compiler, IDE, interpreter, and REPL. Code, compile, and run code in 50+ programming languages: Clojure, Haskell, Kotlin (beta), QBasic, Forth, LOLCODE, BrainF, Emoticon, Bloop, Unlambda, JavaScript, CoffeeScript, Scheme, APL, Lu
repl.it
https://github.com/psf/requests
psf/requests
A simple, yet elegant HTTP library. Contribute to psf/requests development by creating an account on GitHub.
github.com
https://www.crummy.com/software/BeautifulSoup/
Beautiful Soup: We called him Tortoise because he taught us.
www.crummy.com
<코드기록>
# StackOverflow를 하기 전에 indeed 함수식을 여러개로 쪼개서 main.py에 있던 것을 indeed.py로 옮겨줌
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
# 그리고 이 함수식 company 결과값 중 company 정보가 없는 회사들은 None 값이 뜨도록 if문을 수정함
def extract_job(html):
title = html.find("div", {"class": "title"}).find("a")["title"]
company = html.find("span", {"class": "company"})
company_anchor = company.find("a")
if company:
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
else:
company = None
location = html.find("div", {"class": "recJobLoc"})["data-rc-loc"]
job_id = html["data-jk"]
return {
'title': title,
'company': company,
'location': location,
"link": f"https://www.indeed.com/viewjob?jk={job_id}"
}
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
print(f"Scrapping page {page}")
result = requests.get(f"{URL}start={page * LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs
# sof 홈페이지 Webscraping!
# 그러나 None 값이 나와서 진행이 안됨.. (X)
# pages = soup.find("div"..) 이 부분!
# sof홈페이지의 class: "pagination"명이 강의영상때와 다름!
# "pagination" >> "s-pagination"으로 고침! (O)
import requests
from bs4 import BeautifulSoup
URL = f"https://stackoverflow.com/jobs?q=python&sort=i"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class":"s-pagination"}).find_all("a")
print(pages)
def get_jobs():
last_page = get_last_page()
return []1. main.py에 있던 함수식을 indeed.py로 옮기고 이름 간결화하기

indeed.py 자체가 indeed를 지칭하고 있으니, 변수명에 indeed를 넣을 필요가 없어졌다.

mian.py에서 indeed.py에서 새롭게 정의한(def) get_jobs를 가지고 와서 변수명을 설정하고 출력했다.
2. stackoverflow 홈페이지 추출하기, 시작!

sof(stackoverflow)파일을 새로 생성하고, 처음에 indeed에서 requests로 만들었던 식을 복붙했다.
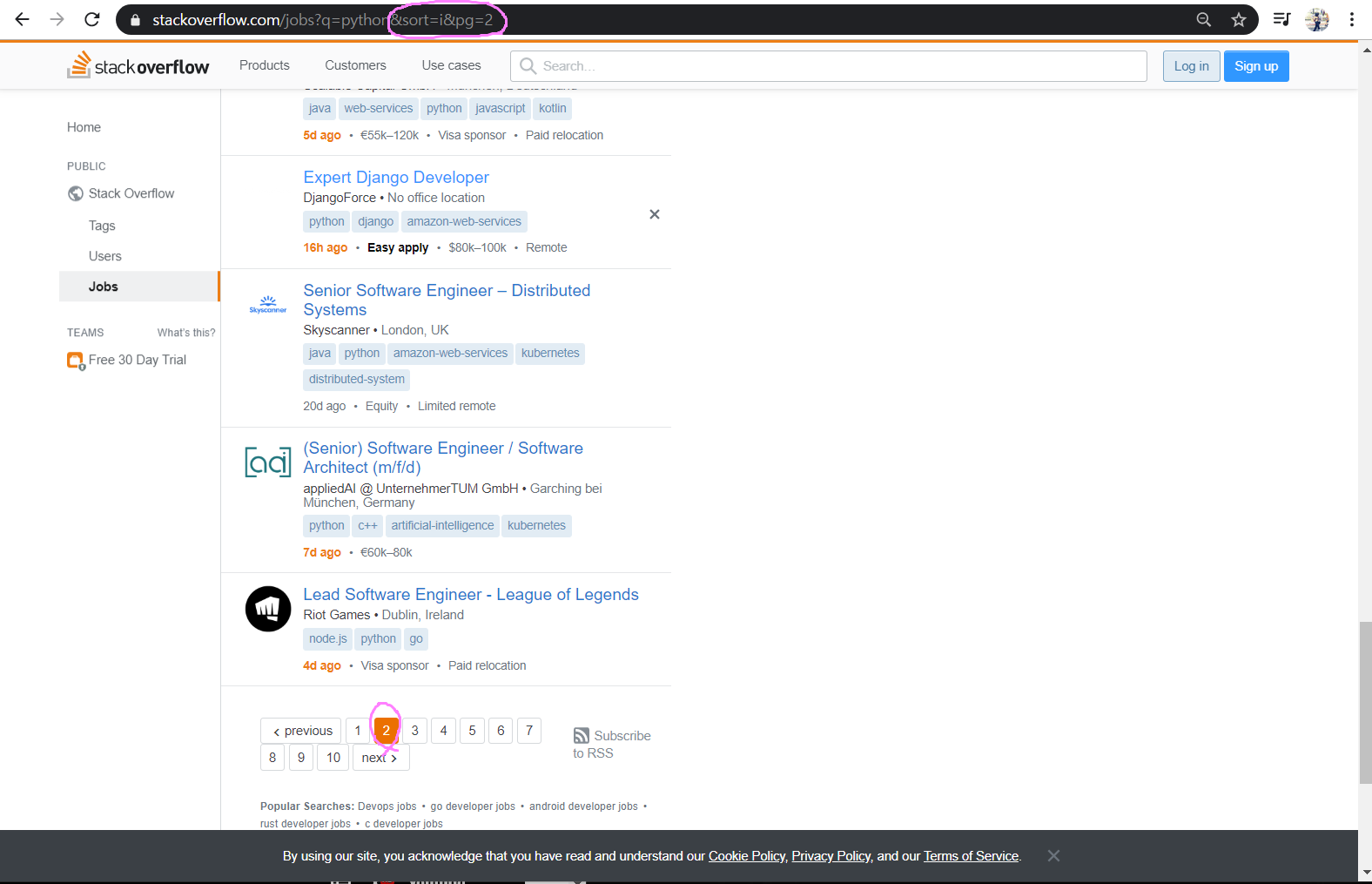
sof(stackoverflow)의 홈페이지의 page 2는 어떻게 나오는지 확인했다. 결과는 &sort=i&pg=2

URL링크 뒤에 &sort=i까지만 가져오고 &pg=2는 지워줬다.
그리고 홈페이지에 LIMIT(페이지수당 몇 개의 직업을 띄울것인가)의 정보가 나와있지 않아서 지워줬다.
3. sof soup 제대로 작동하는지 확인하기

indeed 페이지 추출할 때 처음에 작성한 코드와 동일하다. HTML의 정보를 text로 출력, 성공!
비슷한 함수식 추출하는 것도 나쁘지 않다, div와 anchor가 sof 홈페이지에도 동일하게 있기 때문이다.
그러나 indeed, sof 홈페이지 세부내용 중 다른게 있어 오류가 날 수도 있으니 따로따로 만들었다.

main.py에서 sof에서 정의한(def) get_jobs를 가져오고 실행하려했지만 되지 않았다.
(#은 주석처리, indeed 홈페이지까지 출력하면 안됌!)
()를 적지 않아서 실행 자체가 되지 않았던 것이다. ()가 버튼의 역할을 한다는 것을 명심해야된다.
4. pagination 추가하기

indeed 때와 마찬가지로 BeautifulSoup 기능 중 soup.find.()를 이용해보자.

그리고 홈페이지에 보이는 next도 indeed 페이지 추출할 때와 마찬가지로 신경써줘서 처리해야 된다.
홈페이지 inspection(검사) 터미널 창을 보면, 클릭한 곳이 div class="s-pagination"이라고 되있는 것을 알 수 있는데, 영상에서는 "pagination"으로 나와서 그대로 따라서 코드를 적는 실수를 해서 진행이 더뎠다..
("pagination" - X, "s-pagination" - O)

위에서 말한 것 같이 pagination의 결과값으로 None 값이 나왔다.
(sof홈페이지에 "pagination"이란 값은 존재하지 않음!)

그리고 .find_all("a")로 모든 a(anchor)를 찾으려 하자 'NoneType' object has no attribute 'find all'이라는 오류가 출력됐다.
오류가 난 이유는 계속 말한 것처럼 "pagination"값이 sof홈페이지에는 없기(None)때문!
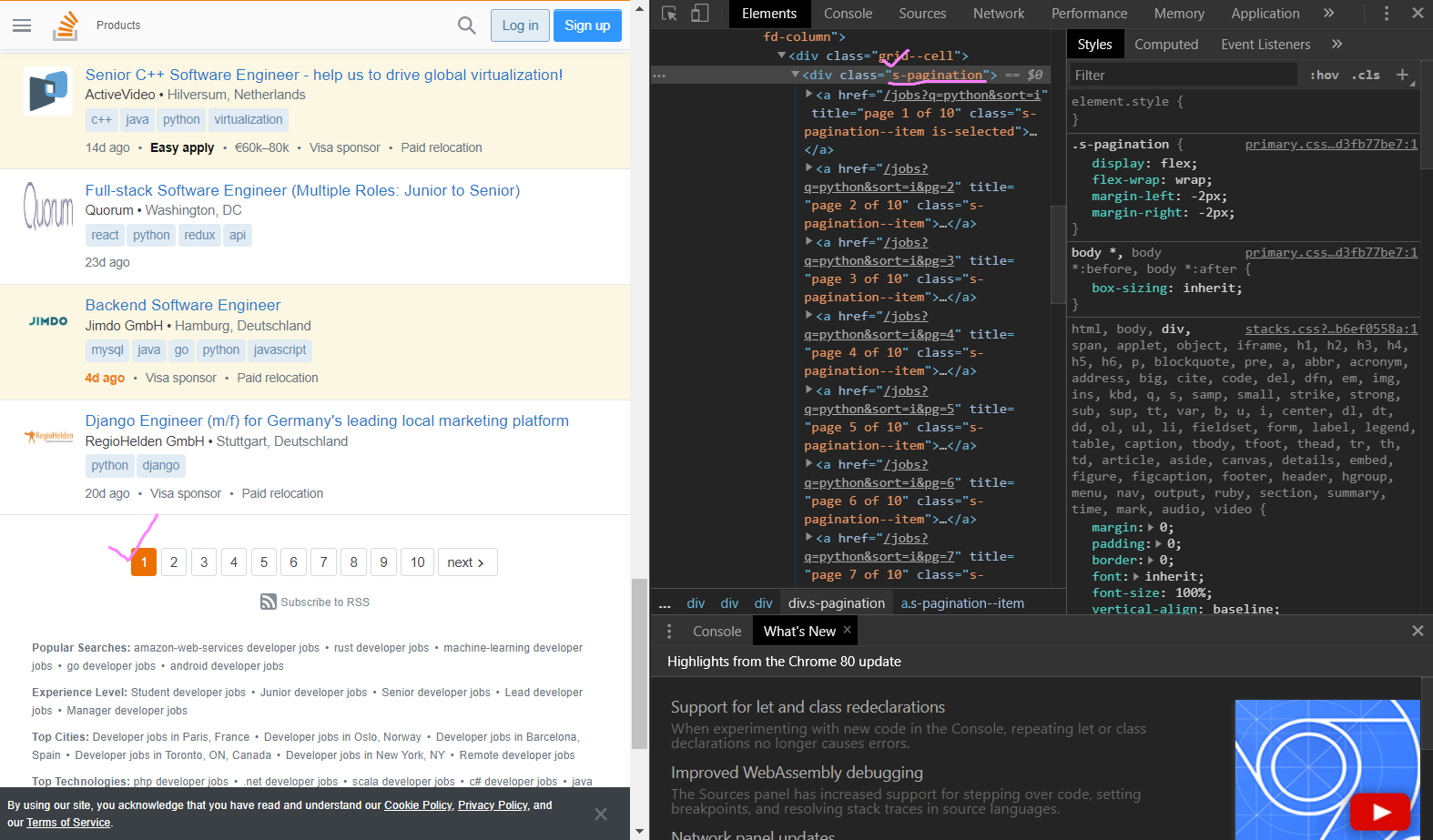
홈페이지에 들어가서 div class="s-pagination"인 것을 다시 확인해주고,

"pagination"을 "s-pagination"으로 변경하고 실행하자, 성공!
마지막으로 Web Scraping 과정을 정리하자면,
1. 페이지 가져오기 (Get the page)
2. request 만들기 (Make the request)
3. job을 추출하기 (Extract the jobs)
끝.
다음 포스팅부터 본격적으로 sof 홈페이지 추출한 것을 정리하도록 하겠다.
※ 코로나바이러스감염증-19 조심하세요!!!!

'Python > Web Scraping' 카테고리의 다른 글
| [Python] #2.11 StackOverflow extract job / #2.12 part Two (#코딩공부) (0) | 2020.02.23 |
|---|---|
| [Python] #2.10 StackOverflow extract jobs (#코딩공부) (0) | 2020.02.22 |
| [Python] #2.8 Extracting Locations and Finishing up (#코딩공부) (0) | 2020.02.21 |
| [Python] #2.7 Extracting Companies (#코딩공부) (0) | 2020.02.20 |
| [Python] #2.6 Extracting Titles (#코딩공부) (0) | 2020.02.19 |




댓글